Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Announcing Apache Kafka 0.10 and Confluent Platform 3.0
I am very excited to announce the availability of the 0.10 release of Apache Kafka and the 3.0 release of the Confluent Platform. This release marks the availability of Kafka Streams, a simple solution to stream processing and Confluent Control Center, the first comprehensive management and monitoring system for Apache Kafka. Around 112 contributors provided bug fixes, improvements, and new features such that in total 413 JIRA issues and 13 KIPs were resolved.
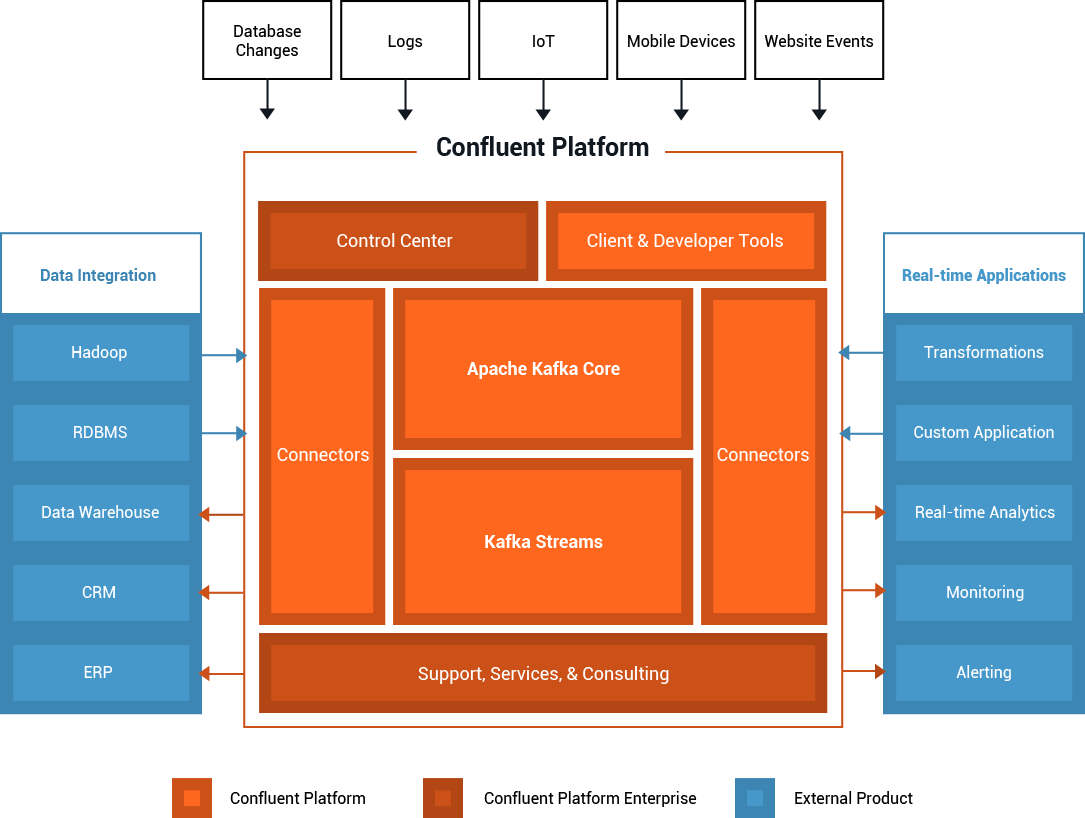
Why Confluent Platform?
For organizations that want to build a streaming data pipeline around Apache Kafka, Confluent Platform is the easiest way to get started. As the original creators of Apache Kafka, we learned from our own and others’ experiences as some of the largest companies in the world transitioned to a central stream data platform and have assembled an open-source, well-tested and fully supported platform of extensions on Kafka that make it more capable and easier to deploy and operate.
Open Source
Confluent Platform is open-source and includes the latest version of Apache Kafka with critical bug fixes, as well as a set of open-source extensions that help you get started with Kafka:
- Connectors: It isn’t enough to just deploy Kafka; you need to connect it to data sources and systems to make it usable. Confluent Platform includes a set of certified and tested connectors that help ingest data into Kafka at scale and in real-time.
- Clients: Apache Kafka offers just the Java clients, though a lot of applications are built in various other programming languages. Confluent Platform includes fully-featured C and Python clients, as well as a REST proxy that enables producing and consuming messages from applications built in any language.
- Metadata management: Confluent Platform offers Schema Registry; a serving layer for your metadata. It is a RESTful interface for storing and retrieving Avro schemas and stores a versioned history of all schemas, provides multiple compatibility settings and allows evolution of schemas according to the configured compatibility setting.
Commercial
The 3.0 release of Confluent Platform introduces the first commercial product through the Confluent Platform Enterprise offering— Control Center. It is a web-based tool for comprehensive management and monitoring of Apache Kafka. In version 3.0.0, Control Center offers two essential components of building streaming data pipelines:
A license for Confluent Control Center is available for Confluent Platform Enterprise Subscribers, but any user may download and try Confluent Control Center for free for 30 days.
What’s new in Apache Kafka 0.10?
Apache Kafka 0.10.0.0 is a major release of Apache Kafka and includes a number of new features and enhancements. Highlights include:
 Kafka Streams: Kafka Streams was introduced as part of the tech preview release of the Confluent Platform few months ago and is now available through Apache Kafka 0.10.0.0. Kafka Streams is a library that turns Apache Kafka into a full featured, modern stream processing system. Kafka Streams includes a high level language for describing common stream operations (such as joining, filtering, and aggregating records), allowing developers to quickly develop powerful streaming applications. Kafka Streams offers a true event-at-a-time processing model, handles out-of-order data, allows stateful and stateless processing and can easily be deployed on many different systems— Kafka Streams applications can run on YARN, be deployed on Mesos, run in Docker containers, or just embedded into existing Java applications.
Kafka Streams: Kafka Streams was introduced as part of the tech preview release of the Confluent Platform few months ago and is now available through Apache Kafka 0.10.0.0. Kafka Streams is a library that turns Apache Kafka into a full featured, modern stream processing system. Kafka Streams includes a high level language for describing common stream operations (such as joining, filtering, and aggregating records), allowing developers to quickly develop powerful streaming applications. Kafka Streams offers a true event-at-a-time processing model, handles out-of-order data, allows stateful and stateless processing and can easily be deployed on many different systems— Kafka Streams applications can run on YARN, be deployed on Mesos, run in Docker containers, or just embedded into existing Java applications.
- Rack Awareness: Kafka now has rack awareness built-in that isolates replicas so they are guaranteed to span multiple racks or availability zones. This allows all of Kafka’s durability guarantees to be applied to these larger architectural units, significantly increasing resilience and availability. Netflix contributed this feature and have used it to deploy Kafka clusters across several availability zones in Kafka on AWS.
- Timestamps in Messages. Thanks to LinkedIn’s contribution, every message in Kafka now has a timestamp field that indicates the time at which the message was produced. This enables stream processing by event-time in Kafka Streams and will enable several features like message look-up by time and accurate event-time based garbage collection.
- SASL Improvements. The 0.9.0.0 release introduced new security features in Apache Kafka, including support for Kerberos through SASL. In 0.10.0.0, Kafka now includes support for more SASL features, including external authentication servers, supporting multiple types of SASL authentication on one server, and other improvements.
- List Connectors and Connect Status/Control REST APIs. In Kafka 0.10.0.0, we have continued to improve Kafka Connect. Previously, users had to monitor logs to view the status of connectors and their tasks, but we now support a status API for easier monitoring. We’ve also added control APIs, which allow you to pause a connector’s message processing in order to perform maintenance, and to manually restart tasks which have failed. The ability to list and manage connectors through an intuitive UI is available through the Control Center.
- Kafka Consumer Max Records. In 0.9.0.0, developers had little control over the number of messages returned when calling poll() on the new consumer. This feature introduces a new parameter max.poll.records that allows developers to limit the number of messages returned.
- Protocol Version Improvements. Kafka brokers now support a request that returns all supported protocol API versions. (This will make it easier for future Kafka clients to support multiple broker versions with a single client.)
Contributors to Apache Kafka 0.10
The Kafka community has actively participated in shipping this release. According to git shortlog, 112 people contributed to this release. Thank you for your contributions!
Adam Kunicki, Aditya Auradkar, Alex Loddengaard, Alex Sherwin, Allen Wang, Andrea Cosentino, Anna Povzner, Ashish Singh, Atul Soman, Ben Stopford, Bill Bejeck, BINLEI XUE, Chen Shangan, Chen Zhu, Christian Posta, Cory Kolbeck, Damian Guy, dan norwood, Dana Powers, David Jacot, Denise Fernandez, Dionysis Grigoropoulos, Dmitry Stratiychuk, Dong Lin, Dongjoon Hyun, Drausin Wulsin, Duncan Sands, Dustin Cote, Eamon Zhang, edoardo, Edward Ribeiro, Eno Thereska, Ewen Cheslack-Postava, Flavio Junqueira, Francois Visconte, Frank Scholten, Gabriel Zhang, gaob13, Geoff Anderson, glikson, Grant Henke, Greg Fodor, Guozhang Wang, Gwen Shapira, Igor Stepanov, Ishita Mandhan, Ismael Juma, Jaikiran Pai, Jakub Nowak, James Cheng, Jason Gustafson, Jay Kreps, Jeff Klukas, Jeremy Custenborder, Jesse Anderson, jholoman, Jiangjie Qin, Jin Xing, jinxing, Jonathan Bond, Jun Rao, Ján Koščo, Kaufman Ng, kenji yoshida, Kim Christensen, Kishore Senji, Konrad, Liquan Pei, Luciano Afranllie, Magnus Edenhill, Maksim Logvinenko, manasvigupta, Manikumar reddy O, Mark Grover, Matt Fluet, Matt McClure, Matthias J. Sax, Mayuresh Gharat, Micah Zoltu, Michael Blume, Michael G. Noll, Mickael Maison, Onur Karaman, ouyangliduo, Parth Brahmbhatt, Paul Cavallaro, Pierre-Yves Ritschard, Piotr Szwed, Praveen Devarao, Rafael Winterhalter, Rajini Sivaram, Randall Hauch, Richard Whaling, Ryan P, Samuel Julius Hecht, Sasaki Toru, Som Sahu, Sriharsha Chintalapani, Stig Rohde Døssing, Tao Xiao, Tom Crayford, Tom Dearman, Tom Graves, Tom Lee, Tomasz Nurkiewicz, Vahid Hashemian, William Thurston, Xin Wang, Yasuhiro Matsuda, Yifan Ying, Yuto Kawamura, zhuchen1018
Notice
Camus in Confluent Platform is deprecated in Confluent Platform 3.0 and may be removed in a release after Confluent Platform 3.1. To export data from Kafka to HDFS and Hive, we recommend Kafka Connect with the Confluent HDFS connector as an alternative.
How do I get Apache Kafka 0.10?
Apache Kafka 0.10 is available through Confluent Platform 3.0.0. Download it to give it a spin. To upgrade Confluent Platform from 2.0.x to 3.0.0, follow the upgrade documentation.
Looking ahead
In the forthcoming releases, the Apache Kafka community plans to focus on operational simplicity and stronger delivery guarantees. This work includes improved data balancing, more security enhancements, and support for exactly-once delivery in Apache Kafka. Confluent Platform will have more clients, connectors and extended monitoring and management capabilities in the Control Center.
Also, now is a great time to get involved. You can start by running through the Kafka quick start, signing up on the mailing list, and grabbing some newbie JIRAs.
If you enjoy working on Kafka and would like to do so full time, we are hiring at Confluent!
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...