Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Tyrannical Data and Its Antidotes in the Microservices World
Data is the lifeblood of so much of what we build as software professionals, so it’s unsurprising that operations involving its transfer occupy the vast majority of developer time across enterprises. But all too often data’s supreme importance drives us to work for it instead of having it work for us—particularly if it lives in a classic single-database system.

Source: “Alcatraz” by Alexander C. Kafka
Single databases quickly grow too big to fail, so we commonly find ourselves in the position of being afraid to disturb our data—finding it too risky to experiment with new structures or platforms, even if they would ultimately be beneficial. As a result, we start designing applications that cater to the database itself, possibly even implementing horrible elements like infinite stored procedures and awkward triggers. But at least our valuable data is safely locked away, given that we have handled it so carefully and guarded it in a single location, right?
Unfortunately not, because data concentration itself brings security risks. It’s like storing every last one of your most valuable possessions in a single safe. Although you may take the best of precautions, it still only takes one regrettable breach for all of your treasures to walk out the front door. In fact, many of the data breaches that you read about in the media are a result of storing sensitive data alongside non-sensitive data in the same database.
Concentrated data can also require extra compliance vetting. For example, operations that only require non-sensitive data from a database that also holds sensitive data need the same PCI compliance as those that work only with sensitive data. Finally, there’s the relatively recent GDPR regulation barring sensitive EU data from being stored on American servers, which has created a whole set of new problems for single-database architectures.
Breaking up the single-database system into microservices
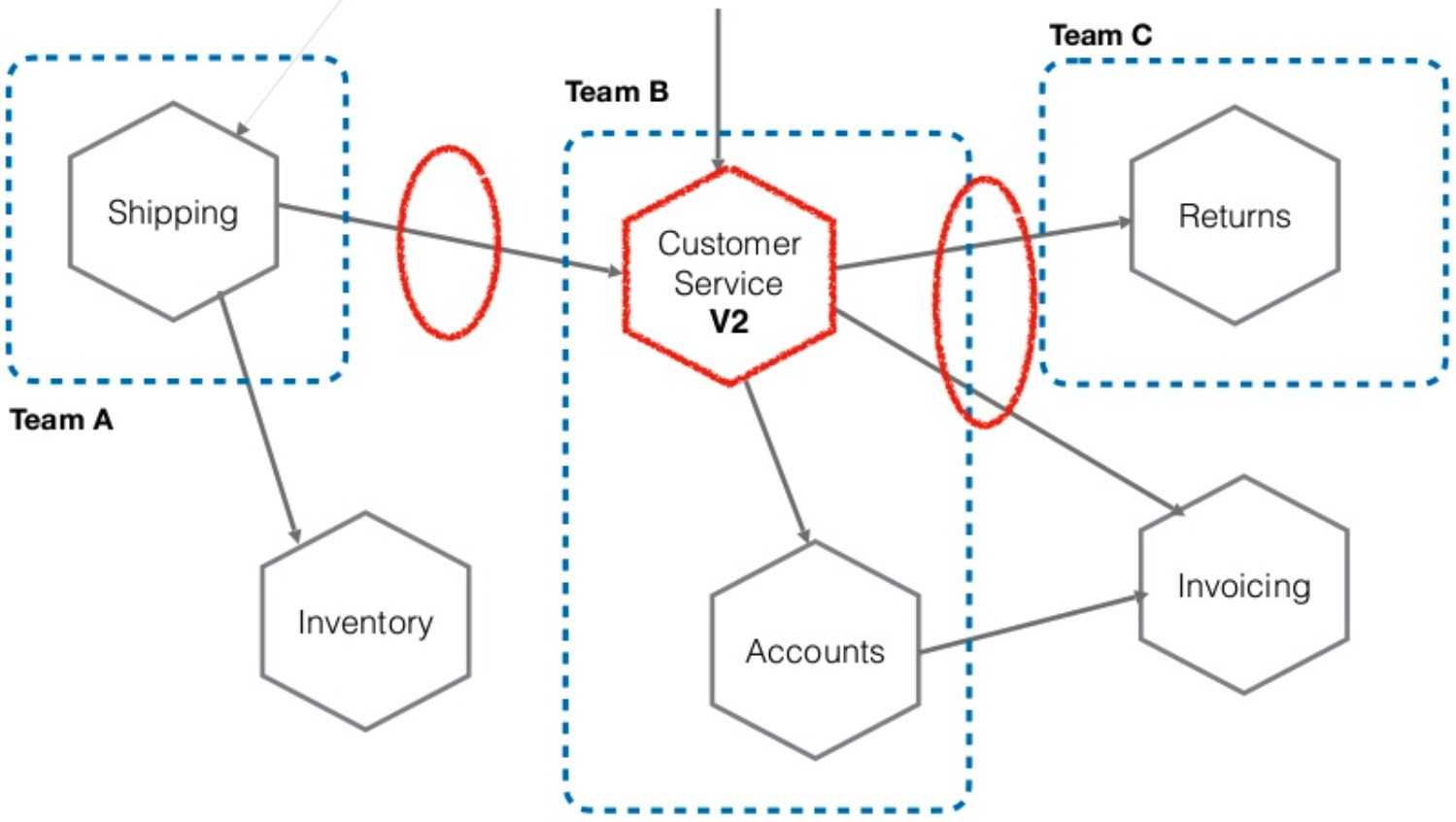
Source: Keynote: Sam Newman, Building Microservices | The Tyranny Of Data | Kafka Summit 2020
Whether your impetus for breaking up your single database system is rooted in security or compliance issues, or in the desire to free your system’s data—microservices are a logical architectural progression.
With respect to security and compliance, a microservices architecture allows you to split your sensitive and non-sensitive data between services. And all services should ideally perform information hiding, as defined by David Parnas, or only share what is necessary to accomplish their respective functions. In fact, the basic act of establishing microservices in the first place forces system architects to make conscientious and beneficial decisions about data exposure. And these decisions are a critical first step in negotiating the data dichotomy inherent to distributed systems.
As far as improving data flow within a system, a primary benefit of microservices is that they optimize for autonomy, a phrase that James Lewis uses to describe what microservices can accomplish for teams within an organization. Microservices can allow teams to function more independently from each other, allowing changes to be made and deployed without requiring high degrees of coordination between teams. By splitting data apart, and hiding it inside our microservice boundaries, we make this independent deployability and therefore the improved organizational autonomy much easier. Indeed, the number one reason that companies adopt a microservices architecture is because it lets large companies with many developers function efficiently.
So it is clear that breaking up data into microservices, whether necessarily or aspirationally, can yield remarkable benefits. Nevertheless, such a reorganization also has its pain points.
Lost and Found: Relational Qualities Restored by an Apache Kafka® Pipeline
One of the primary elements that you lose when you move from a single-database model to a microservices architecture is a shared place where all of your data can easily be interchanged.
Apache Kafka gives you the chance to bring this data back together again, allowing you to create a data backbone for your entire architecture, all whilst still allowing your microservices to maintain a high degree of autonomy. Another Kafka feature that alleviates some of the pain points of shifting from a single-database architecture is its data permanence: New services can easily come online and immediately download all of the history from other services.
However, there is also a more direct way to use Kafka and microservices along with relational features like joins and ad hoc queries: Simply add a reporting database to your ecosystem. Basically, this means that you funnel your Kafka event stream into a relational database. Once the data is there, you can query it as usual or bring it into a BI tool like Tableau or QlikView. Although this uses the same relational technology that we intentionally escaped with our transition to microservices, it is entirely different to use the technology and not be dependent on it for critical operations.
The reporting database pattern is certainly a classic and sturdy one for analytics, but it admittedly does give off the sense that it exists in somewhat of an old-fashioned, end-of-day analytics world. What about more recent developments that can help us with real-time data challenges?
SELECTs across data sources: Push queries in ksqlDB
One particularly capable contemporary upgrade to tooling in the data space are the push queries in ksqlDB, which resemble constantly updating SELECT statements written in SQL-like syntax.
Using push queries, for example, you could join a streaming total of orders for the day with a list of order categories in real time, with continuously running queries. And you could take this operation far beyond SELECTs, as push queries support a full set of SQL. Generally, push queries save you from writing application logic, and they work particularly well with asynchronous workflows.
ksqlDB also lets you perform traditionally functioning SELECTs when you need them with pull queries, whereby you send a command and receive a response.
Conclusion
By adopting microservices with Kafka, we move from a world where we had to work for our data to one where we recognize that if we break our data apart, we can make it work for us, which will in turn make our teams more productive.
Although this admittedly brings challenges, some of the more recent developments in ksqlDB and the Kafka ecosystem go to show that we have come up with solutions to many of them.
To learn more about these ideas, watch my keynote from Kafka Summit 2020, or you can check out the Streaming Audio podcast, hosted by Tim Berglund, where I talk about them in depth as well.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Unlocking Data Insights with Confluent Tableflow: Querying Apache Iceberg™️ Tables with Jupyter Notebooks
This blog explores how to integrate Confluent Tableflow with Trino and use Jupyter Notebooks to query Apache Iceberg tables. Learn how to set up Kafka topics, enable Tableflow, run Trino with Docker, connect via the REST catalog, and visualize data using Pandas. Unlock real-time and historical an...



Shifting Left: How Data Contracts Underpin People, Processes, and Technology
Explore how data contracts enable a shift left in data management making data reliable, real-time, and reusable while reducing inefficiencies, and unlocking AI and ML opportunities. Dive into team dynamics, data products, and how the data streaming platform helps implement this shift.