Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Building Shared State Microservices for Distributed Systems Using Kafka Streams
The Kafka Streams API boasts a number of capabilities that make it well suited for maintaining the global state of a distributed system. At Imperva, we took advantage of Kafka Streams to build shared state microservices that serve as fault-tolerant, highly available single sources of truth about the state of objects in our system.
Why we chose Kafka Streams
At Imperva, a recognized cybersecurity leader, one type of service that we offer is distributed denial-of-service (DDoS) protection for websites, networks, IPs, and other assets. The agents in our system—WAF proxies, Behemoth scrubbing appliances, etc.—observe these assets and their traffic. Based on their observations, we construct a formal state for each object or asset. For example, for a website, its state can be under DDoS attack or not under DDoS attack, and for a protected network, its connectivity state can be up or down.
Prior to introducing Kafka Streams, we relied in many cases on one single central database (plus a service API) for state management. This approach came with downsides: in data-intensive scenarios, maintaining consistency and synchronization becomes a challenge, and the database can become a bottleneck or be prone to race conditions and unpredictability.
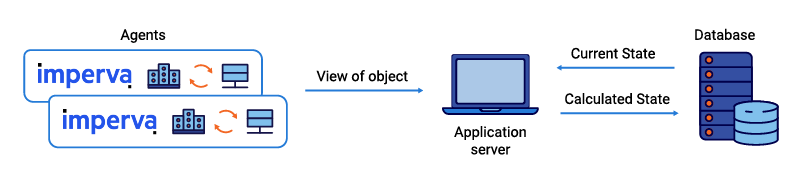
Figure 1. Typical shared state scenario before we started using Apache Kafka® and Kafka Streams: agents
report their views via an API, which works with a single central database to calculate updated state.
About a year ago, we decided to give our shared state scenarios an overhaul that would address these and other concerns. We defined the following requirements for the new shared state microservices that would be built:
- A uniform way to consume events, construct shared state (using varying algorithms), and generate shared state events
- An API for checking state and performing maintenance
- Scalability, high availability, and fault tolerance
- A built-in scheduling mechanism
Kafka Streams made it possible to meet all these requirements, and the following sections provide more details on how.
A unified approach to shared state
At the core of each shared state microservice we built was a Kafka Streams instance with a rather simple processing topology. It consisted of (1) a source, (2) a processor with a persistent key-value store, and (3) a sink:
protected Topology getStreamsTopology() {
Topology topologyBuilder = new Topology();
topologyBuilder.addSource(SOURCE_NAME, getSourceTopicName());
topologyBuilder.addProcessor(PROCESSOR_NAME, getProcessor(), SOURCE_NAME);
topologyBuilder.addStateStore(Stores.keyValueStoreBuilder(Stores.persistentKeyValueStore(
getStoreName(), getKeySerdeForInputTopic(), getValueSerdeForInputTopic()), PROCESSOR_NAME);
topologyBuilder.addStateStore(Stores.keyValueStoreBuilder(Stores.persistentKeyValueStore(
getSchedulingStoreName()), Serdes.String(), Serdes.String(), PROCESSOR_NAME);
return topologyBuilder;
}
In this new approach, agents produce messages (representing state change events) to the source topic, and consumers—such as a mail notification service or an external database—consume the calculated shared state via the sink topic.
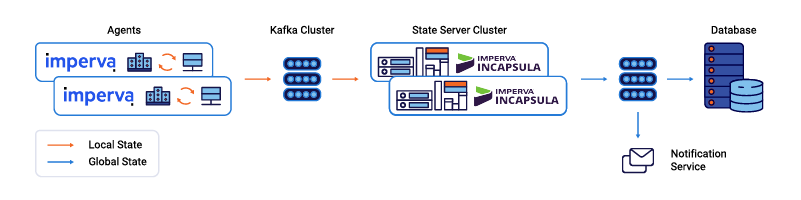
In a simple scenario where the formal state of an object is always equal to the latest state reported for this object by an agent, persisting the state as is in the key-value store during processing (more on why later) and then forwarding it to the sink suffices. The following snippets depict such a case:
public abstract class BaseSharedStateProcessor<SourceValueT, ResultValueT> extends
AbstractProcessor<String, SourceValueT> {
private KeyValueStore kvStore;
@Override public void init(ProcessorContext context) { super.init(context); setKVStore((KeyValueStore<String, ResultValueT>) context.getStateStore(getStoreName())); }
private void setKVStore(KeyValueStore kv) { kvStore = kv; }
@Override public void process(String key, SourceValueT value) { doProcess(key, value, kvStore); } }
public class ExampleDataProcessor extends BaseSharedStateDataProcessor<String, String> { @Override public void doProcess(String key, String value, KeyValueStore<String, String> keyValueStore) { keyValueStore.put(key, value); // here we could consult the keyValueStore and calculate a // value based on it context().forward(key, value); // forward to next processor (in our case sink topic) context().commit(); // flush it } }
However, having a key-value store makes it possible to also support more complex state calculation algorithms, such as majority vote or at-least-one. For example, in the case of a majority vote, the value in the store for each object can consist of a mapping between each agent and its latest report on the object. Then, when a new state report is received for some object from an agent, we can persist it, re-run the majority vote calculation, and forward the result to the sink.
Building a CRUD API on top of Kafka Streams
Another requirement for our shared state microservices was to provide a RESTful CRUD API. We wanted to make it possible to retrieve the state of some or all objects on demand, as well as set or purge the state of an object manually, which is useful for backend maintenance.
To support the state retrieval APIs, whenever we calculate a state during processing, we persist it to the built-in key-value store. The API then becomes quite easy to implement using the Kafka Streams instance, as seen in the snippet below:
private ReadOnlyKeyValueStore<String, SharedStateWriteModel> getStateStore() {
return Main.getStreams().store(getStoreName(), QueryableStoreTypes.<~>keyValueStore());
}
private SharedStateWriteModel getValueFromStore(String key) {
return getStateStore().get(key);
}
Updating the state of an object via the API was also easy. It involved creating a Kafka producer and producing a record consisting of the new state. This ensured that messages generated by the API were treated in exactly the same way as those coming from other producers (i.e., agents):
protected void updateKafkaRecord(String id, SharedStateWriteModel state) {
Producer<String, SharedStateWriteModel> producer = buildProducer();
ProducerRecord<String, SharedStateWriteModel> data = buildProducerRecord(id, state);
producer.send(data);
producer.close();
}
Benefits and challenges of moving from one microservice to a cluster
Next, we wanted to distribute the processing load and improve availability by having a cluster of shared state microservices per scenario. Setup was a breeze—after configuring all instances to use the same application ID and the same bootstrap servers, everything pretty much happened automatically. We also defined that each source topic would consist of several partitions, with the aim that each instance would be assigned a subset of these.
With regard to preserving the state store (in case of failover to another instance, for example), Kafka Streams creates a replicated changelog Kafka topic for each state store in which it tracks local updates. This means that the state store is constantly backed up in Kafka. So if some Kafka Streams instance goes down, its state store can quickly be made available to the instance that takes over its partitions. Our tests showed that this happens in a matter of seconds, even for a store with millions of entries.
Moving from one shared state microservice to a cluster of microservices made implementing the state retrieval API more complex. Now, each microservice’s state store held only part of the world: the objects whose key was mapped to a specific partition. We had to determine which instance held the specified object’s state using the Streams metadata:
public Response getState(String key, HttpServletRequest request) throws Exception {
int partition = getPartition(key); // get the id of the partition that the given key maps to
KafkaStreams streams = getStreams();
StreamsMetadata partitionStreamsMetadata = getPartitionStreamsMetadata(partition,
streams.allMetadata());
if (isFoundInLocal(partitionStreamsMetadata)) { // check if pod name and port in streams
// metadata are equal to local
SharedStateReadModel state = sharedStateService.get(key);
return Response.status(Response.Status.OK).entity(state).build();
} else {
String url = getRedirectUrl(partitionStreamsMetadata, request); // redirect using the
// host name in streams meta
return redirect(url);
}
}
Task scheduling made easy
One more requirement for our shared state microservice was the ability to schedule both a one-time and periodic task in response to an incoming message. For example, when an agent reports some state for an object, we want to wait five minutes, check if the state stayed the same, and only then forward it to the sink.
Fortunately, the processor context, which is passed on to the processor during init, provides a schedule method that does just that. We used it with the WALL_CLOCK_TIME type. For achieving one-time tasks, we used the cancellation handle returned by it. Additionally, our processing topology includes a second key-value store for scheduling. We used it to persist metadata about each scheduled task (interval, task fully-qualified class name, key, etc.), so that in the event of failover, the tasks could be rescheduled during init by the instance that takes over the partition.
Here’s an example of how we schedule a task from within the processor using the scheduler we implemented:
DemoRecurringTask demoRecurringTask = new DemoRecurringTask(key,
(KeyValueStore) context().getStateStore(getStoreName()));
scheduler.scheduleTask(demoRecurringTask, 5000);
Below is what our scheduler looks like. The scheduling data access object is responsible for updating the scheduling metadata key-value store, and BaseSharedStateTask is an abstract class implementing Kafka Streams’ Punctuator interface.
public class SharedStateScheduler {
private static final Logger logger = LoggerFactory.getLogger(SharedStateSchduler.class);
private ProcessorContext processorContext;
private SharedStateSchedulingDao schedulingDao;
public SharedStateScheduler(ProcessorContet processorContext, SharedStateSchedulingDao dao) {
this.processorContext = processorContext;
this.schedulingDao = dao;
}
public void scheduleTask(BaseSharedStateTask task, long interval) {
Cancellable cancellationHandle = processorContext.schedule(interval,
PunctuationType.WALL_CLOCK_TIME, task);
task.setCancellationHandle(cancellationHandle);
task.setSchedulingDao(schedulingDao);
if (task.getId() == null) {
task.setId(UUID.randomUUID().toString());
schedulingDao.addScheduledTask(task.getKey(), task.getId(), interval,
task.getClass().getName());
}
}
public void resumeTasks() {
KeyValueIterator schedulingStoreIterator = getSchedulingStore().all();
while (schedulingStoreIterator.hasNext()) {
String key = (String) ((KeyValue) schedulingStoreIterator.next()).key;
Map<String, String> scheduledTasksMeta = schedulingDao.getScheduledTasksMeta(key);
for (String taskId : scheduledTasksMeta.keySet()) {
String taskMeta = scheduledTasksMeta.get(taskId);
String taskFQCN = SharedStateSchedulingDao.getFQCNFromMeta(taskMeta);
Long interval = SharedStateSchedulingDao.getIntervalFromMeta(taskMeta);
if (taskFQCN != null && interval != null) {
try {
Constructor constructor = Class.forName(taskFQCN).getConstructor(String.class,
KeyValueStore.class);
BaseSharedStateTask task = (BaseSharedStateTask) constructor.newInstance(key,
getStateStore());
task.setId(taskId);
scheduleTask(task, interval);
} catch (Exception e) {
logger.error(“Failed to resume task for key “ + key, e);
}
}
}
}
}
private KeyValueStore getSchedulingStore() {
return (KeyValueStore) processorContext.getStateStore(getSchedulingStoreName());
}
private KeyValueStore getStateStore() {
Return (KeyValueStore) processorContext.getStateStore(getStoreName());
}
}
Lessons learned
Overall, Kafka Streams has proven to be very robust in our production environment. We did initially encounter a few cases where Kafka Streams shut itself down in production and identified two causes for these shutdowns, as outlined below:
- Sometimes, due to problems in our agent machines which produce the messages to Kafka, the messages are sent with a negative timestamp. Kafka Streams’ default behavior in such cases is to shut down, in order to protect against silent data loss. However, this behavior can be changed in cases where dropped messages with bad timestamps are acceptable, such as ours. This is done by using a different timestamp extractor class (configured via the StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG property). For our shared state microservices, we chose to extend the LogAndSkipOnInvalidTimestamp extractor class in order to be able to both log the problem and update some metrics accordingly.
- We also noticed that when Kafka Streams experienced prolonged connection timeouts to Kafka, it eventually shut itself down. To reach stability, we increased the value of a few streams configuration properties:
- ProducerConfig.RETRIES_CONFIG
- ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG (producer only)
- ProducerConfig.MAX_BLOCK_MS_CONFIG (this was needed in order to overcome metadata update timeouts)
Kafka Streams ticks all the boxes
As this blog post has shown, Kafka Streams ticks all the boxes required for building shared state microservices, as far we’re concerned.
- Its key-value stores allow persisting the shared state and can serve as a de facto distributed database, constantly replicated to Kafka
- Auxiliary data can also be stored in the key-value stores, enabling complex shared state construction algorithms
- Generated shared state events can be consumed via the processing topology’s sink topic
- High-availability and fault tolerance are provided out of the box, using Kafka’s built-in coordination mechanism
- A scheduling service can easily be implemented using Kafka Streams’ built-in scheduling abilities
- A CRUD API for shared states is also not hard to implement: writing can be done using a local Kafka producer, while reading is possible using the Streams instances.
Using Kafka Streams, we’ve been able to shorten development times and bring uniformity to our code. We look forward to further expanding on its potential!
Interested in more?
If you’re interested in learning more about Kafka Streams and all things Kafka, this is a good opportunity to mention that Kafka Summit San Francisco is just around the corner. You can register and get 30% off with the code blog19.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.