Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Confluent 3.2 with Apache Kafka® 0.10.2 Now Available
We’re excited to announce the release of Confluent 3.2, our enterprise streaming platform built on Apache Kafka. At Confluent, our vision is to provide a comprehensive, enterprise-ready streaming platform that includes the latest in streaming technology from Apache Kafka.
Our latest release includes significant upgrades to our operational and monitoring tool, Confluent Control Center, new .NET and JMS clients, a new Amazon Simple Storage Service (S3) connector, as well as Apache Kafka 0.10.2.
New in Confluent
.NET and JMS Clients
In a recent survey, 72% of respondents stated they use 2 or more languages with Apache Kafka and 59% said they use a language other than Java. Only Confluent offers multi-client support for leading languages, now including a .NET client that fully supports the Windows developer ecosystem, including C# and other .NET languages. Apache Kafka developers looking to run streaming workloads in a .NET environment can now use a fully supported and tested client from Confluent that even supports Active Directory for authentication. It’s available as part of Confluent Open Source and is already proving a popular choice on Github!
Many industries still depend on legacy applications to run their businesses, from finance to manufacturing. Confluent 3.2 includes a new client to support legacy Java Message Service (JMS) applications consuming and producing directly from Kafka. To further secure deployments we’ve also added data-in-transit encryption on the Confluent REST Proxy. JMS is available in Confluent Platform, and the REST Proxy is available in Confluent Open Source.
.NET and JMS expand our list of supported clients in Java, Python, Go, and C++, which are rigorously tested for performance and reliability and fully support the Apache Kafka protocol. Additionally, Python now integrates with the Confluent Schema Registry in addition to Java and C++.
In the Cloud, Bridge to Cloud
The new Confluent S3 Connector simplifies cloud-native and bridge-to-cloud deployments, leveraging the Kafka Connect API to write to S3. The S3 connector guarantees exactly once delivery, writes Avro and JSON, supports date and time based partitions, and can automatically infer and evolve data formats and schemas based on events in Apache Kafka. Learn More
Operate at Scale
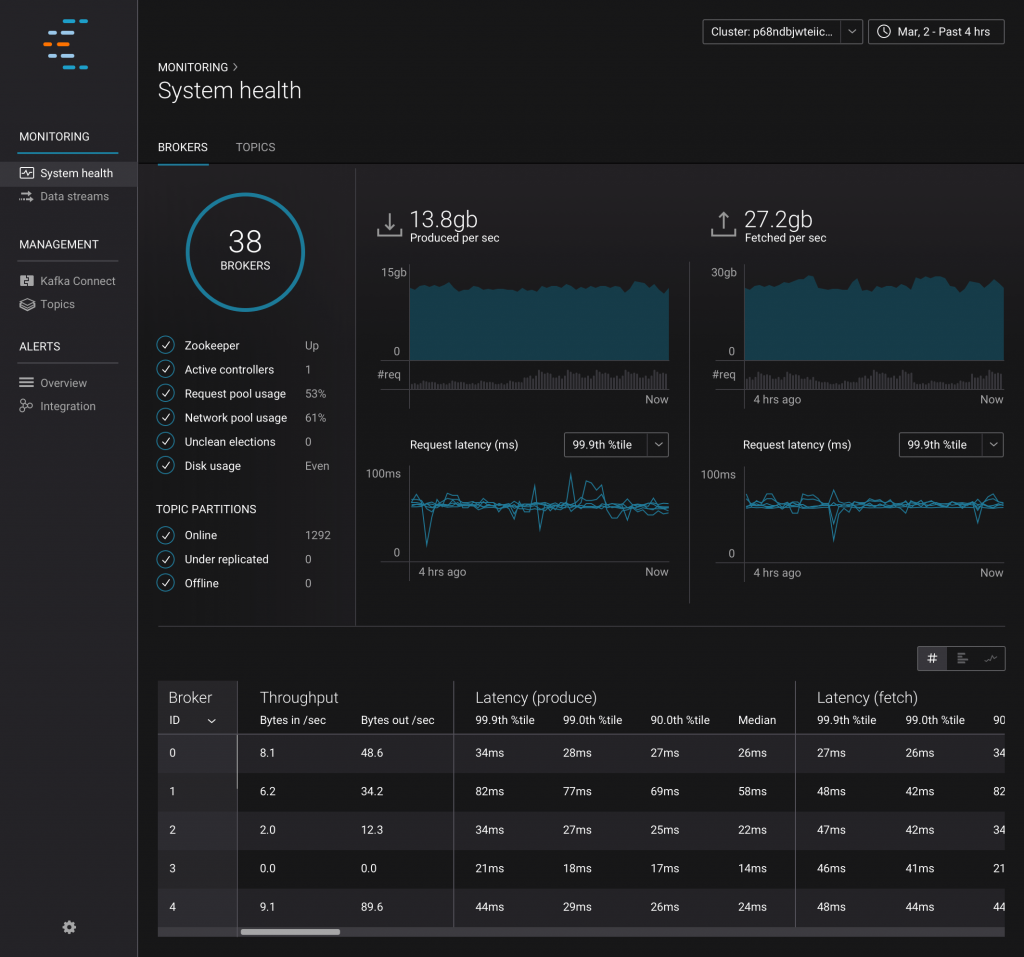
Confluent Control Center, the solution for management, monitoring, and administration of Apache Kafka clusters, includes significant new monitoring and alerting features for clusters, brokers and topics. Leveraging the experience Confluent has with dozens of the world’s largest Kafka installations, Control Center can distill over 150 different metrics from a running cluster into a manageable set of KPIs and supporting details to provide both broker-centric and topic-centric snapshots of platform health, encoding operational best practices right into the product. Learn More
Confluent Control Center is part of Confluent Platform, which includes Multi-Datacenter Replication and Auto Data Balancing capabilities to operate seamlessly at scale.
New in Apache Kafka
Confluent Platform 3.2 includes Apache Kafka 0.10.2, which contains a number of performance and bug fixes, a significantly improved compatibility policy, and notable feature improvements including:
- Over 200 bug fixes and performance improvements: As always, the release includes a huge number of bug fixes and performance improvements. Details here.
- Java Client Compatibility: The newest Java Clients now support older brokers (0.10.0 and higher), which significantly improves the compatibility story.
- Single Message Transformations for the Connect API in Kafka: Modify events before they make it into Kafka, or on the way out. This is a great way to mask sensitive fields such as PII, filter fields and columns from an event, normalize data formats, convert data types or route events into the correct table, index, bucket or topic.
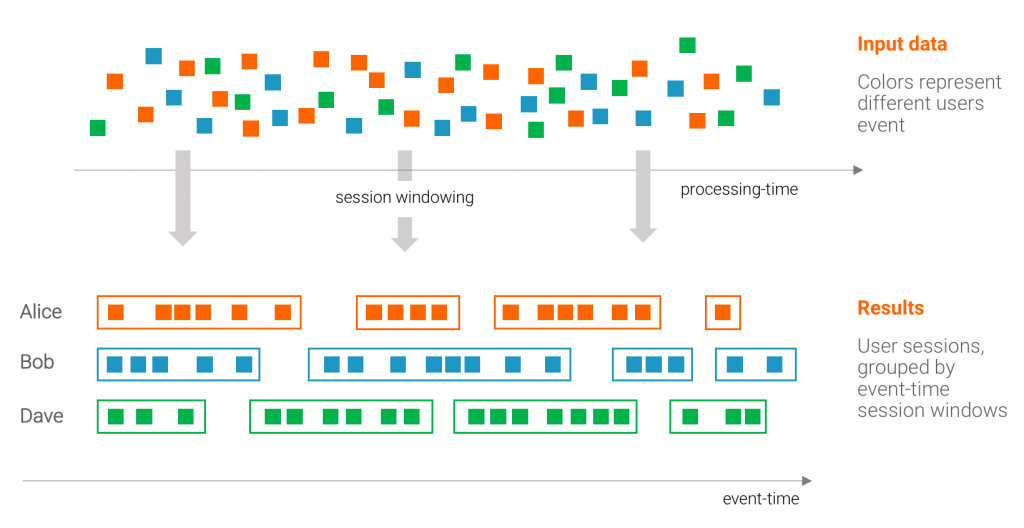
- Session Windows in Kafka’s Streams API: Aggregate events into sessions based on periods of inactivity, rather than fixed time windows (for instance, session timeouts in behavioral analytics are usually 30 minutes.)
- Global Table Support in Kafka’s Streams API: Join streams of data without complex re-keying or re-partitioning.
Full details are available in the Apache Kafka Release Notes.
Getting Started
The easiest way to get started is to install either our free open source product, Confluent Open Source, or a free 30-day trial of Confluent Platform. Details for both can be found on our download page or you can learn more by reading our documentation.
Confluent Platform 3.2 is backed by our subscription support. We also offer expert training and technical consulting to help get your organization started. As always, we are happy to hear your feedback. Please post your questions and suggestions to the public Confluent Platform mailing list, or join our new community Slack channel!
To learn more about Confluent 3.2 and Apache Kafka 0.10.2, join us for an online talk series that will dive further into each of the new key features. Register now.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...