Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Continuous Deployment of Confluent with Ansible Tower
When self-managing Confluent, provisioning and configuring Apache Kafka® deployments along with the rest of the Confluent components involves many hurdles, such as managing infrastructure, installing software, and configuring security. And deployment is just the beginning of the operations journey. This blog post introduces you to the GitOps pattern and shows you how tools like cp-ansible and Ansible Tower can simplify the deployment process.
cp-ansible is an open source set of Ansible roles and playbooks maintained by Confluent, designed to simplify your Confluent deployment and operations. Ansible Tower is an enterprise automation server provided by Red Hat that allows you to manage Ansible playbooks—schedule deployments, manage credentials, and monitor hosts and deployments. By adding cp-ansible jobs to your Tower, you can automate your Confluent deployments across the organization.
Infrastructure as code with CP-Ansible
As your infrastructure footprint scales, it becomes increasingly important to make your deployment process simple and repeatable. If you are standing up a web server on a single virtual machine (VM), you might be able to make the case for manually configuring that host, but when it comes to 100-node Kafka clusters, it’s best to follow the GitOps pattern. GitOps starts with representing your deployment as code.
cp-ansible uses inventory files as infrastructure as code (IaC). Here is a sample of a cp-ansible inventory file:
all:
vars:
ansible_become: true
ssl_enabled: true
zookeeper:
hosts:
ip-172-31-40-189.us-west-2.compute.internal:
ansible_host: ec2-34-217-174-252.us-west-2.compute.amazonaws.com
ip-172-31-45-239.us-west-2.compute.internal:
ansible_host: ec2-52-33-35-38.us-west-2.compute.amazonaws.com
ip-172-31-38-126.us-west-2.compute.internal:
ansible_host: ec2-54-187-141-233.us-west-2.compute.amazonaws.com
kafka_broker:
hosts:
ip-172-31-34-194.us-west-2.compute.internal:
ansible_host: ec2-34-221-165-177.us-west-2.compute.amazonaws.com
ip-172-31-32-169.us-west-2.compute.internal:
ansible_host: ec2-54-212-210-86.us-west-2.compute.amazonaws.com
ip-172-31-39-180.us-west-2.compute.internal:
ansible_host: ec2-35-162-16-54.us-west-2.compute.amazonaws.com
In the above inventory file, there are three groups defined: all, zookeeper, and kafka_broker. Under a group, there can be hosts and variables. The all group is a simple way to apply variables to all hosts defined in the file. A full inventory file will have more groups and variables defining which Confluent components should be installed on which hosts and how cp-ansible should configure them.
To follow GitOps, you should save your inventory file in a Git repository. Next, use cp-ansible and Ansible Tower as a deployment tool to turn your inventory file into a deployment.
Integrating CP-Ansible with Ansible Tower
Ansible Tower is an automation server that manages Ansible playbook runs. It saves your logs, and has a GUI. To set up cp-ansible within Ansible Tower, there are many steps you need to follow. The below script uses the AWX command line interface to automate all setup tasks:
echo "________Create Default Organization________" awx organizations create --name Defaultecho "Create cp-ansible project" awx projects create --wait
--organization Default --name='CP-Ansible'
--scm_type git --scm_branch='6.1.1-post'
--scm_url 'https://github.com/confluentinc/cp-ansible'echo "Create inventory project" awx projects create --wait
--organization Default --name='AWS Infrastructure'
--scm_type git --scm_branch='master'
--scm_url $REPO_URLecho "Create Inventory" awx inventory create
--organization Default --name='AWS Infrastructure'echo "Create Inventory Source from Inventory Project" awx inventory_sources create
--name='AWS Infrastructure'
--inventory='AWS Infrastructure'
--source_project='AWS Infrastructure'
--source scm
--source_path='terraform/hosts.yml'
--update_on_project_update trueecho "Create Machine Credential from SSH Key" awx credentials create --credential_type 'Machine'
--name 'AWS Key' --organization Default
--inputs '{"username": "centos", "ssh_key_data": "@'${HOME}'/.ssh/id_rsa"}'echo "Create Deployment Job" awx job_templates create
--name='Deploy on AWS' --project 'CP-Ansible'
--playbook all.yml --inventory 'AWS Infrastructure'
--credentials 'AWS Key'echo "Associate Machine Credential to Job" awx job_template associate
--credential 'AWS Key' 'Deploy on AWS'
The full script is provided in an accompanying demo, but note that the “Create inventory project” step uses a Git repo for its source. It is possible to store your inventory files within Tower itself, but Git is the preferred way to keep in line with GitOps.
After the script completes, you can go into the Tower UI and trigger the “Deploy on AWS” job. Here is a screenshot of the output:
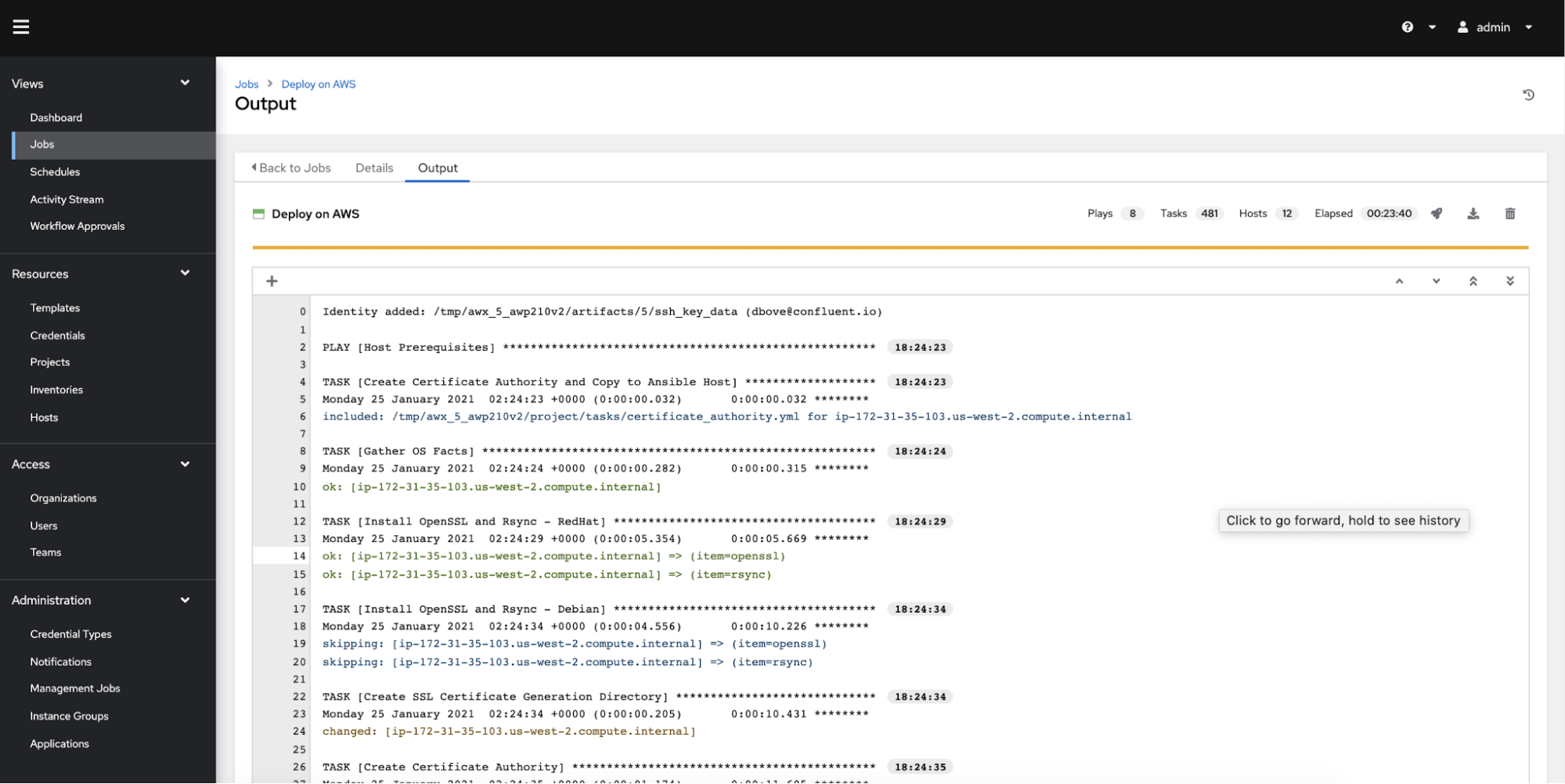
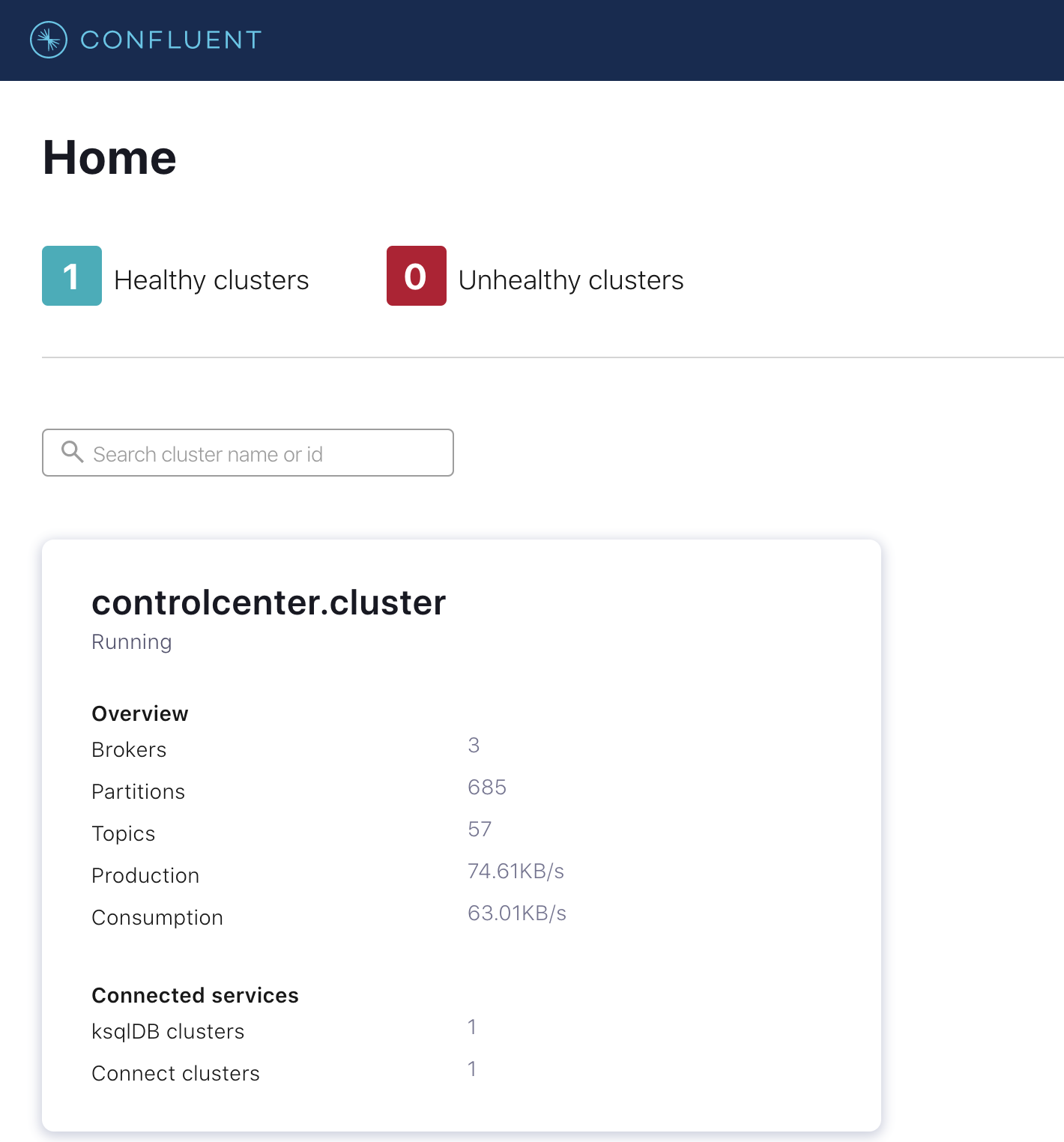
After the job completes, Confluent Platform is deployed and Confluent Control Center can be accessed.
CP-Ansible on Ansible Tower demo
For continuous deployment of Confluent with Ansible Tower, run through the Ansible Tower demo. The demo uses Docker Compose to deploy Confluent Platform on AWS infrastructure.
Next steps for self-managing Confluent
Ansible Tower has the Git webhooks capabilities, which means that updates to your inventory file within Git can trigger the cp-ansible deployment job. Starting with cp-ansible 6.1.0, there is support for reconfiguration. Turning this on achieves continuous deployment with zero downtime! You can push changes to your inventory file and they will automatically update on your hosts.
Don’t want to manage Confluent and Kafka yourself?
This blog post provides a solution for Kafka deployments. But there is still more work on the operations journey to complete, such as tuning, monitoring, scaling, and upgrading. cp-ansible assists with some operations, but it is your ops team’s responsibility to manage. To alleviate the operational burden, look to Confluent Cloud, a fully managed service for Apache Kafka that means you don’t have to worry about ops and can get to streaming. Sign up for Confluent Cloud and receive $400 to spend within Confluent Cloud during your first 60 days. In addition, you can use the promo code CL60BLOG for an extra $60 of free Confluent Cloud usage.*
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...