Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Integrating Elasticsearch and ksqlDB for Powerful Data Enrichment and Analytics
Apache Kafka® is often deployed alongside Elasticsearch to perform log exploration, metrics monitoring and alerting, data visualisation, and analytics. It is complementary to Elasticsearch but also overlaps in some ways, solving similar problems. ksqlDB, the event streaming database purpose-built for stream processing applications, likewise complements the Elasticsearch ecosystem while offering different approaches to handling certain scenarios. ksqlDB and Elasticsearch combined are among the best-of-breed tools to support data enrichment and transformation as well as alerting before ingestion into Elasticsearch where the search and analytics can take place.
What is Elasticsearch?
Before diving in, perhaps you’re wondering what Elasticsearch even is. Elasticsearch is a distributed search engine/datastore built on top of Apache Lucene™ that can be used for a variety of use cases beyond text search. These use cases can leverage the innovative data structures and features in Apache Lucene, including fast Boolean queries, auto-suggest, geo-point queries, and numeric or time series queries.
Other features of Elasticsearch build on top of rich aggregation capabilities that can group the data according to different criteria (e.g., by region, SKU, and geographic region) and calculate incredibly fast aggregations such as sums, averages, and statistical summaries, or anomaly detection on the fly at query time. The platform powers different use cases, such as enterprise search, application performance monitoring (APM), threat monitoring & detection, and anomaly detection, to name a few.
What is ksqlDB?
ksqlDB allows you to write SQL queries on streams from various sources, create derived streams and materialized tables (using push queries), and perform database-like lookups on those materialized tables (using pull queries). Examples of sources include relational databases via change data capture (CDC) connectors, a Twitter feed stream, or sensors sending Internet of Things (IoT) data. The data might need to be filtered or transformed into other shapes for specific applications or downstream systems. To filter, transform, join, or create aggregations from streams of data, you generally have three options:
- Batch-based ETL tools
- Enterprise application integration frameworks, such as Apache Camel
- Stream processing engines, such as Apache Samza, Apache Flink®, or Kafka Streams
However, for simple scenarios where we would like to avoid writing Java or Scala, as well as avoid the overhead of provisioning the clusters for the aforementioned stream processing engines, we can use ksqlDB. The ability to use a declarative language like SQL is a significant advantage over lower-level stream processing systems in the data ecosystem. A five-line ksqlDB statement’s equivalent in Kafka Streams or other stream processing frameworks might well be 10 times as long. Since ksqlDB is built on Kafka Streams, it is also scalable and fault tolerant.
ksqlDB applications persist their output to Kafka topics that can then be consumed by applications downstream. These applications might be reacting to some security event like shutting down a user’s access, or they might be populating materialized views in databases or search engines (via Kafka Connect) that then power dashboards or reports.
At face value, ksqlDB contains some similarities to Elasticsearch:
- Once data is in Elasticsearch, you can query or filter your data via the rich query DSL as well as SQL via the Elasticsearch SQL API. ksqlDB naturally has SQL as its query language for creating continuous queries that feed streams or materialized views.
- You can perform rich multi-level aggregations in Elasticsearch such as sums, averages, group bys, statistics, anomaly detection, etc., on time windows very quickly. This is what drives things like Kibana or Grafana visualisations on Elasticsearch data. ksqlDB supports various aggregations like SUM or AVG and also has the ability to hook in user-defined aggregation functions (UDAFs) to do the same.
- You can process data to enrich, reformat, or drop data before being ingested into Elasticsearch via the Ingest API. ksqlDB has the ability to apply filters via SQL WHERE clauses to create derived streams. In addition, connectors defined via CREATE connectors can be configured with Single Message Transforms and type converters to reformat or drop data.
- You can alert on data arriving into Elasticsearch that meet some criteria within given time windows using Elasticsearch alerting and notify external systems like email, Slack, etc., or just create records within specific Elasticsearch indices to log those alert events. The result of ksqlDB streams or tables can be be pushed out to external systems by configuring connectors within ksqlDB.
- You can use the Elastic percolator to match data against saved queries for as categorization or alerts. This is probably the closest thing in Elasticsearch to ksqlDB or Kafka Streams in that it is a query that matches future-arriving data. ksqlDB’s CREATE STREAM AS SELECT (CSAS) is the basis for querying future data arriving into Kafka for a given criteria.
Why would you use ksqlDB if some of its capabilities come out of the box in Elasticsearch?
It might help to look at where Kafka and ksqlDB fit into data pipelines with various systems.
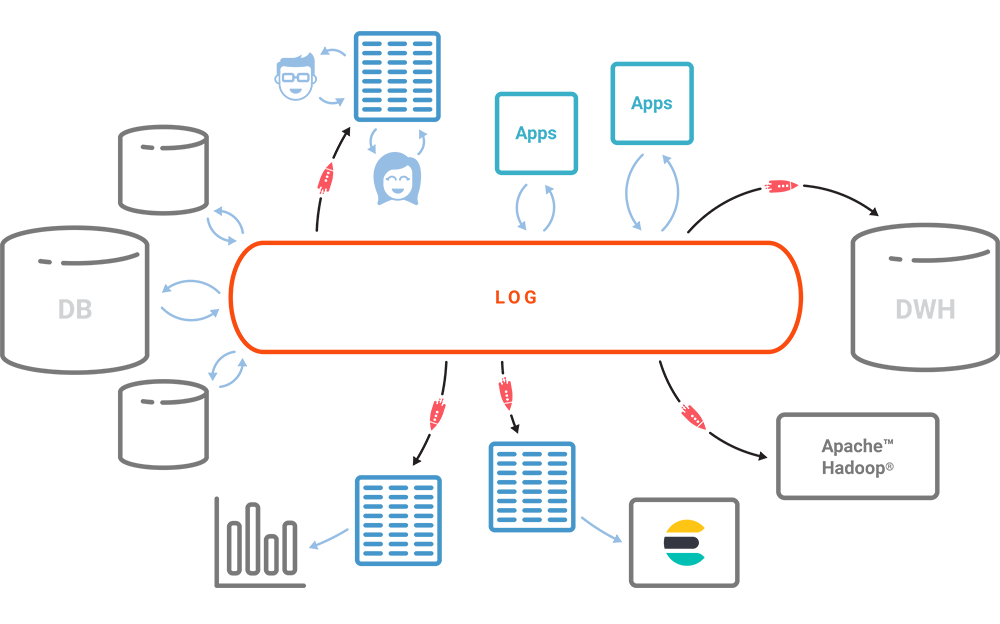
Where Elasticsearch is simply used as a large log search or metrics engine, Kafka is often deployed as a high-throughput buffer between data producers and Elasticsearch. In these use cases, Kafka helps with the data extraction process to ensure that the producers don’t overwhelm the Elasticsearch cluster, to provide scalability, and to more loosely couple the producers with Elasticsearch.
However, where Kafka is used as a central nervous system collecting event data from a wide variety of different systems, Elasticsearch may just be one of many downstream systems that stores the raw or transformed data for querying or analytics capabilities such as search or business intelligence (BI). In this case, Elasticsearch acts as yet another materialized view that can drive applications such as dashboards, data exploration, or reporting. Since different downstream applications may need the data to be shaped for their needs, the transformation (the T in ETL) or pattern detection may need to happen earlier and as soon as the data arrives in the pipeline.
On the pattern detection side, Elasticsearch’s fast indexing and querying capabilities allow you to mimic real-time or near-real-time detection or reactions to interesting events even though they are still polling based on the data that is indexed. With polling-based approaches, edge cases that miss events on window boundaries or late-arriving data for lookups are more likely. In polling-based or micro-batching systems, different problems can arise (e.g., dealing with windowing or late arrival of data).
When building an event-driven architecture, ksqlDB shines in these areas:
- ksqlDB has the ability to configure Kafka connectors (either in embedded mode or by integrating with a Kafka Connect cluster) to sources and sinks. It can also pull data into Kafka. This greatly simplifies the user experience of setting up an end-to-end data pipeline.
- Input data is immutable and derived streams can be recreated from the input history if there was an updated requirement. It does not require a separate batch job.
- ksqlDB can keep mutable materialized views refreshed (via a KTable) but also can create change streams (through Kafka Streams) as required. Using the same mechanisms and applications, it can either query the latest state or receive changes.
- Applications can query the materialized tables (KTables) for simple lookups via REST to get the latest state.
- ksqlDB can process different formats of data (i.e., CSV, JSON, and Apache Avro™) within ksqlDB in the same way. The data does not have to be saved as JSON first before being able to query it.
- Data can be filtered out or transformed before it enters Elasticsearch and other systems within ksqlDB quite easily while keeping the original input data to push to other systems, such as Amazon S3 or Azure Blob Storage. In many cases, you might have a smaller Elasticsearch cluster and only store the important events that occur rather than filling it up with terabytes of raw input data.
- Since ksqlDB is built on Kafka Streams, you can react to data arriving on a message-by-message basis as opposed to using polling queries at specific intervals. This is useful in use cases that require reacting to events as soon as they are detected rather than after a certain window of time has passed. You can also deal with slightly late-arriving data using different window types.
- You can scale the queries that match newly arriving data by scaling out ksqlDB and Kafka partitions, whereas some components in Elasticsearch have limited horizontal scalability (e.g., percolator and alerting).
- You can pipe transformed data or events anywhere downstream via Kafka Connect or through any custom application consuming result topics instead of using web hooks or constantly polling for changes in a result index.
- Since each transformation does not destroy the original data but creates new data in new topics by default, we can keep composing new data (via JOINs) out of intermediate transformations easily using SQL queries. Composing and refreshing derived data within Elasticsearch requires scripting or developing external applications that have to poll and index the results.
- Creating custom user-defined functions (UDFs) or user-defined aggregation functions (UDAFs) is extremely easy and effective in integrating logic for transformation or lookups that don’t fall neatly within plain SQL queries. The usability of named UDFs and UDAFs is easier for Java developers when it comes to certain tasks compared to Elasticsearch’s inline scripting language. Some have used UDFs and UDAFs to call out to machine learning models.
With these advantages, we can see that Kafka and ksqlDB can be used to build event-driven applications that transform, enrich, and react to data as it arrives. This complements Elasticsearch, where you can send the data for long-term storage and analytics.
ksqlDB and Elasticsearch deployment architectures
Typically, we would deploy Kafka in front of Elasticsearch and use Kafka Connect to push data from selected Kafka topics to Elasticsearch.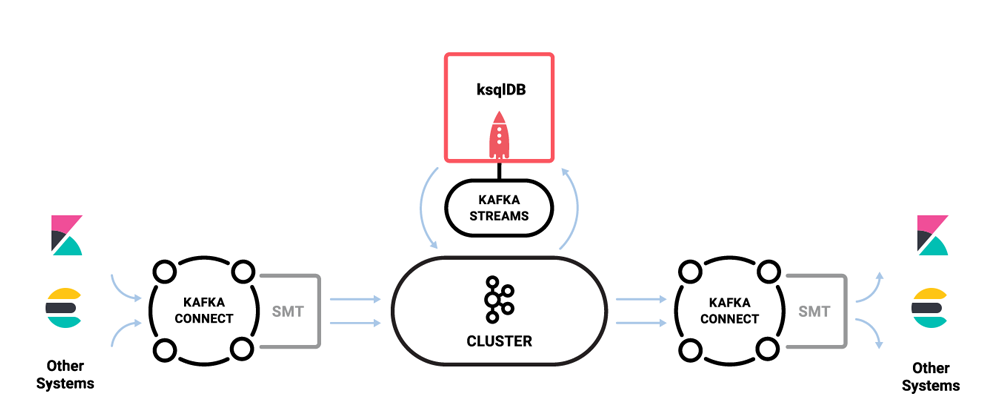
Since ksqlDB can configure Kafka connector jobs within ksqlDB itself, this greatly simplifies the process of setting up Connect jobs for sources and sinks (including Elasticsearch).
In fact, you can take data that’s stored in Elasticsearch—whether it was ingested directly or derived from queries—and get it into Kafka as well. For example, your data analysis or machine learning might provide a list of bad actors that you would like to load as a blacklist into ksqlDB for joining access logs in another topic. These might be events that have been transformed or filtered in a certain way using Elasticsearch queries, or it might take the form of curated reference data which could be used to join or enrich data in ksqlDB.
Conclusion
We’ve covered some of the features of ksqlDB and Elasticsearch, as well as highlighted some of the similarities and subtle differences of each when it comes to building real-time data products. With ksqlDB, we are able to enrich and filter data further upstream from Elasticsearch and send the data in a denormalized fashion for easy analysis and reporting. This can be done in real time as data comes in and not after the fact via a batch process or at query time.
This step-by-step demo shows you how to set up data streams and tables using ksqlDB to send data to Elasticsearch for analysis and visualisation in Kibana. If you’d like to get started with the Kafka Connect Elasticsearch Sink Connector, you can read Danny Kay and Liz Bennett’s blog post to learn more.
I hope this has given you a flavour of what is possible with these technologies and inspires you to create more innovative applications using these patterns.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.