Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Event Streaming Across Networks and Corporate Firewalls Using PubNub and Confluent Platform
This year’s pandemic has forced businesses all around the world to adopt a “remote-first” approach to their operations, with an emphasis on better enabling collaboration, remote work, and productivity. This applies to essential workers, such as delivery personnel, healthcare providers, and manufacturers, remote workers, and consumers. Although our lives have been greatly disrupted due to lockdown measures and economic impact, we continue to conduct our lives online via shopping, learning, messaging, gaming, and other activities. Modern software design is also taking a remote-first mindset to ensure that users can collaborate and share within each app, including the ability to interact with real-time data.
In partnership between Confluent and PubNub, we are proud to introduce the PubNub Bridge for Apache Kafka® with Confluent Platform (currently in Beta), which makes it easy to drive real-world actions from events and insights generated from within the Confluent Platform.
| ℹ️ | If you’d like, you can skip right to the tutorial on how to implement the bridge. |
This bridge makes it easy to unlock business value by making critical insights instantly actionable around the world, across public and private networks, without the need for complex IT projects to keep the data secure. Ultimately, this bridge will help enterprises—including those in highly regulated industries like financial services, insurance, and healthcare—to better capitalize on event-based data. Examples include:
- Live alerts, notifications, and actions
- Share real-time alerts with workforce, partners, and/or customers
- Notify front-line workers with real-time information
- Trigger real-time actions across connected devices (price updates, orders, dispatch requests, route optimization, IoT device control, etc.)
- Mobile workforce transformation
- Better empower workers given rapid workplace shifts, spanning full-time employees to freelancers, contractors, part-timers, and even temps
- Scale up/down easily for holiday or transient workers, or for those impacted by pandemic-induced lockdowns or economic contraction
- Bring-your-own-device (BYOD) environments
- Achieve productivity gains and cost savings by interfacing securely with personally owned devices (laptops, tablets, smartphones, etc.) and using those devices to access privileged company information in real time
- Better support a remote-first business approach, capitalizing on the increasing propensity to use personally owned devices at work (globally)
- Personalization and localization
- Engage customers and prospects through relevant content, promotions, and offers
- Capture market demand by location-based advertising, and drive customers from online to brick-and-mortar stores by targeting potential customers who are nearby
By using the PubNub Bridge for Apache Kafka with the Confluent Platform (or PubNub Bridge), there is no longer a need to build or maintain a complete public-facing API interface to gain access to event-based data from Kafka and Confluent, meaning that application servers, REST interfaces, load balancing, high availability, and observability are no longer necessary. Additionally, there is no need to involve enterprise IT teams for opening firewall ports or adding DNS entries. It just works—reliably, securely, and with enough scale to support global deployment of any size.
With the PubNub Bridge, you can connect mobile and web apps directly to your Kafka topics bidirectionally. This means that you can send and receive messages on your Kafka topics directly in a web browser and on a mobile application. One common use case is managing notifications to users with Kafka. Users can receive notifications based on actions they took, like pressing a button, or in response to actions taken by remote or third parties. These third-party or remote actions can be meaningful to other users, and the action can generate notifications for distant users. Here are some examples:
- Your placement in the queue has been updated from 10th to third. Two minutes estimated wait time remaining.
- Your meeting is starting and the host is admitting participants.
- A new message has arrived in your inbox.
- The driveway camera video detects movement.
- Gamer A invites you to join a game.
While these individual actions can trigger a broadcast of updates for users, there are some actions that can be aggregated for new types of notifications.
The advantage of processing aggregative calculations can be leveraged across multiple use cases, one simple example being live polling or vote tallying for virtual events—including second-screen experiences for TV broadcasts. You can use ksqlDB with a time window to accomplish the tally count. The tally is then ready to be broadcast to the audience at any scale, and the totals can be broadcast incrementally, which allows an early viewing of poll results. However, getting users updates on these results can be tricky. They are, after all, on a WAN IP and do not have access to the streams in Kafka.
In another industry like retail, you can broadcast up-to-the-moment, highly personalized, and limited-availability promotional offers. In healthcare, you could easily send caregiver alerts capitalizing on amalgamations from various real-world data sources. And for transportation, this would make it much easier to keep tabs on the entire supply chain for logistics network optimization.
One last example is recording user behavior. This can be useful for analysis, which leads to improved user experiences. But in order for this analysis to occur, these generated events need to make their way into a Kafka topic securely and durably.
Gateway access to Kafka topics for mobile apps
Spinning up a gateway may seem fairly simple, but in reality, it is often fraught with complexity. First, you must translate the Kafka binary protocol over TCP into a web- and mobile-friendly Layer 7 WAN protocol, such as HTTP, MQTT, or WebSockets. Next, you need encryption, access controls (read/write), auditability, throttling via quotas or rate limits, filtering, durability, low-latency and end-device connectivity status indication (i.e., whether the device is connected), transformability to change message hierarchy, and augmentation ability enabled by adding more data into the message for specific users and target devices.
What follows are other considerations as well.
Broadcast and unicast messages
Applications are not uniform in system utilization and are based on patterns and design. Each use case is different and requires non-homogeneous workload capacity. Broadcasting updates to users requires instant access to network and CPU resources. The delivery of messages to user inboxes will trigger ACKs. The volume of message delivery and accompanying ACKs needs a topology that allows for these compute resources. Additionally, unicast workloads are needed for individual users. These two workloads compete for resources.
Reliability tolerance to faults
Message delivery with gateways should share the durability parameters provided by Kafka when needed. Retry and redelivery of messages is necessary for devices that are joining/leaving networks. What happens if one of the gateways fails? Can another gateway take over for missed deliveries?
Edge geographical connectivity
Not only does latency suffer if all devices are connected to the same datacenter but there are also important local compliance concerns to consider when connecting to end devices: data residency, privacy legislation (i.e., GRPC, HIPAA, and CCPA), and more.
Support for multiple types of devices
The three leading platform languages for web consist of Swift/Objective-C, Kotlin/Java, and JavaScript. Each of these targets needs to be in parity with the list of requirements that we’ve mentioned up to this point.
These complexities, among others, is why we’ve launched the PubNub Bridge for Kafka.
PubNub Bridge for Apache Kafka with Confluent Platform
Your application has protected data stored in a Kafka topic. Getting this data between systems and mobile requires gateway APIs, firewalls, and security that must be in place for each application. We’ve described the work required to grant access to Kafka topics for mobile and web applications above, but here’s another way that is a little bit easier.
PubNub’s Edge Messaging Platform offers a unified approach to securely connecting your data to mobile devices from event sources like Kafka inside out to mobile devices and back. Up until this point, this article has explored the high-level and theoretical ways you can implement PubNub and Confluent Platform for event streaming, but now let’s dive into a practical and hands-on demonstration of how to actually use PubNub’s bridge for Kafka.
To start off this demo, you need to have Docker installed. Docker is used for running the sample Kafka/ZooKeeper feed, so if you don’t have it, make sure to download Docker and install it first.
Docker is not required to run the bridge in production. We provide an alternative non-container bridge install later in this post.
Step 1: Get up and running with Kafka, ZooKeeper, and a sample feed
If you already have a Kafka cluster, you can skip to step 2.
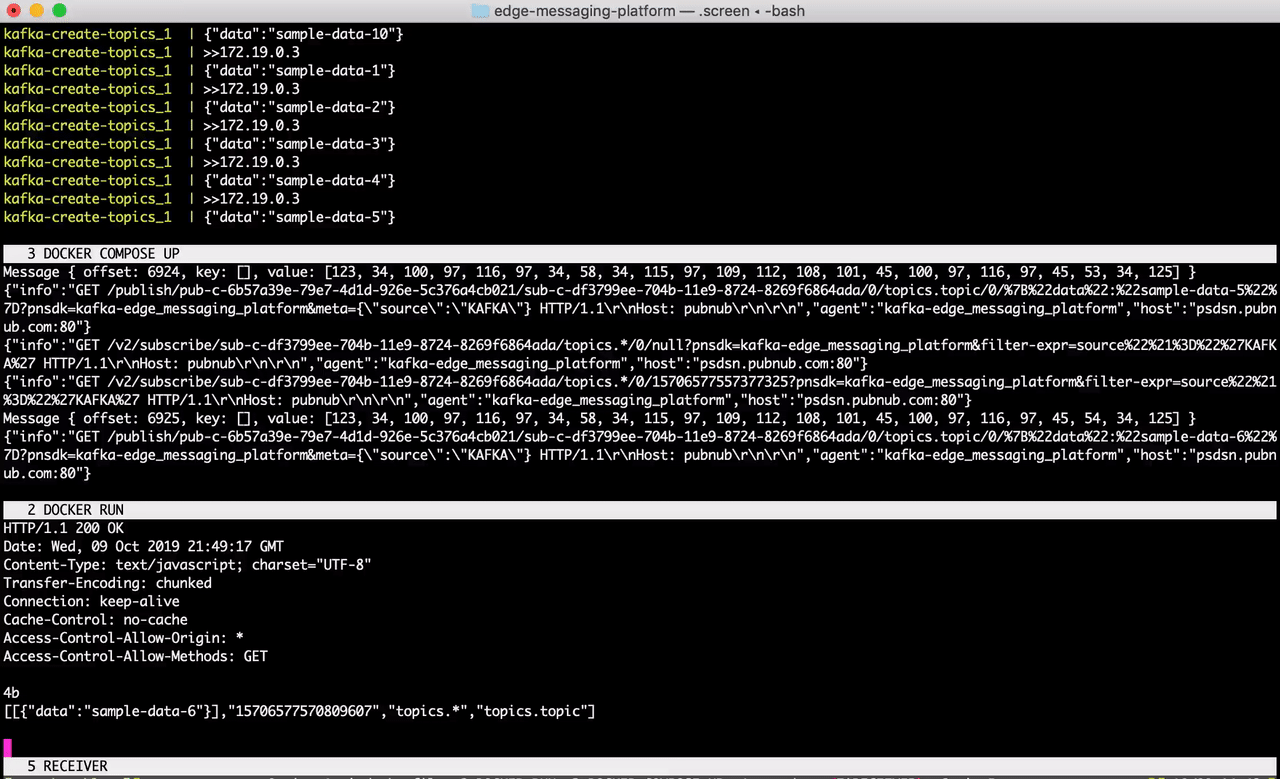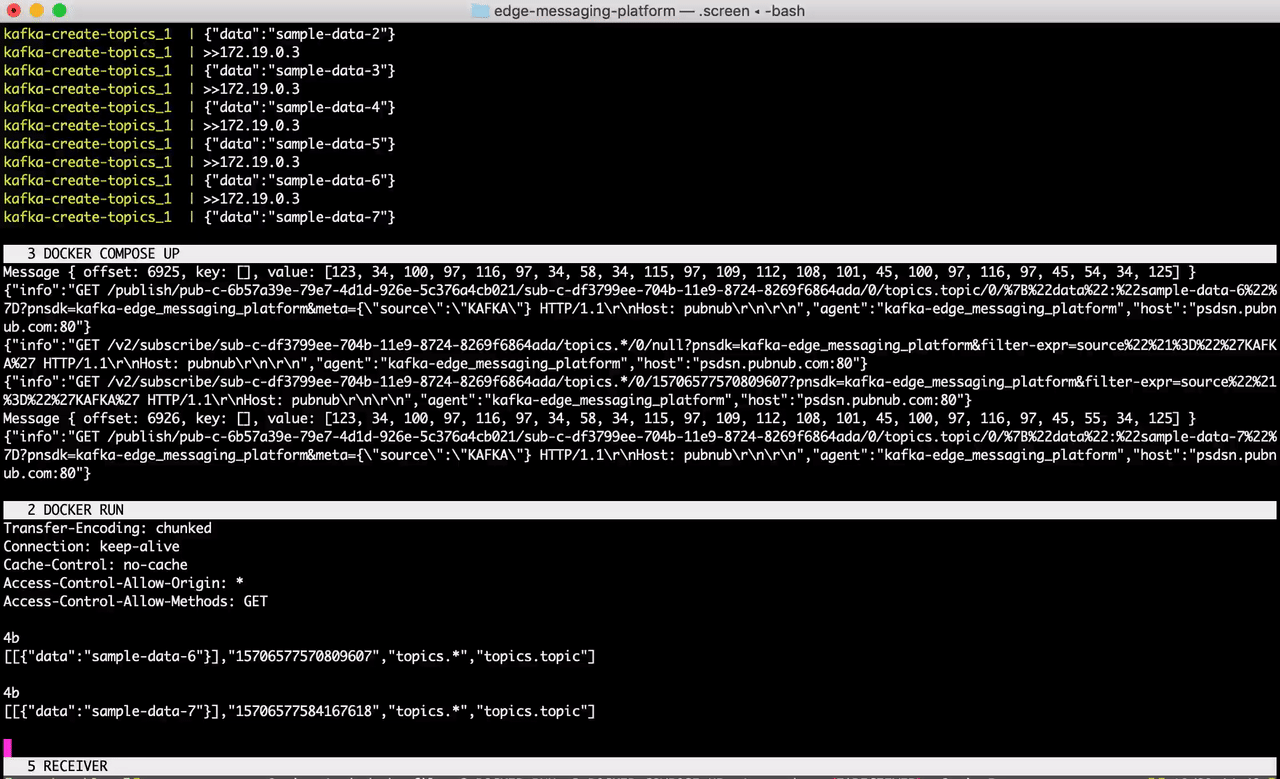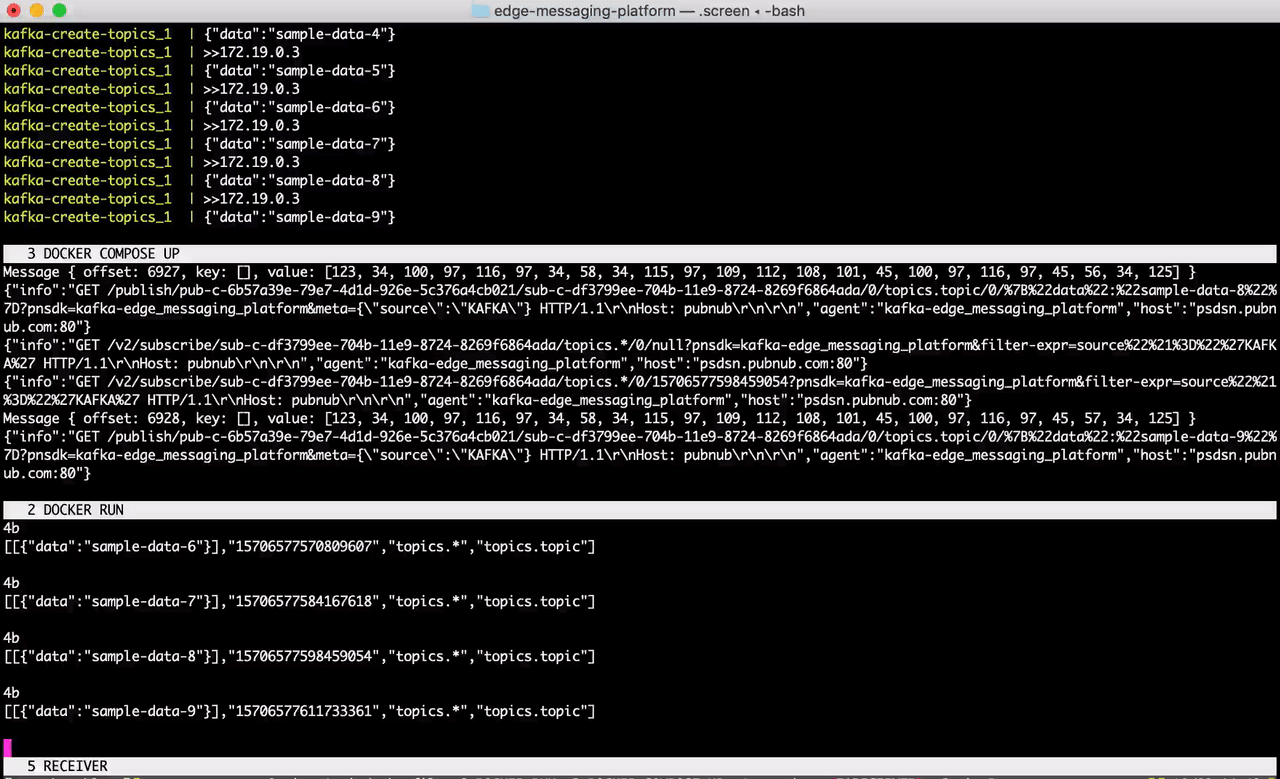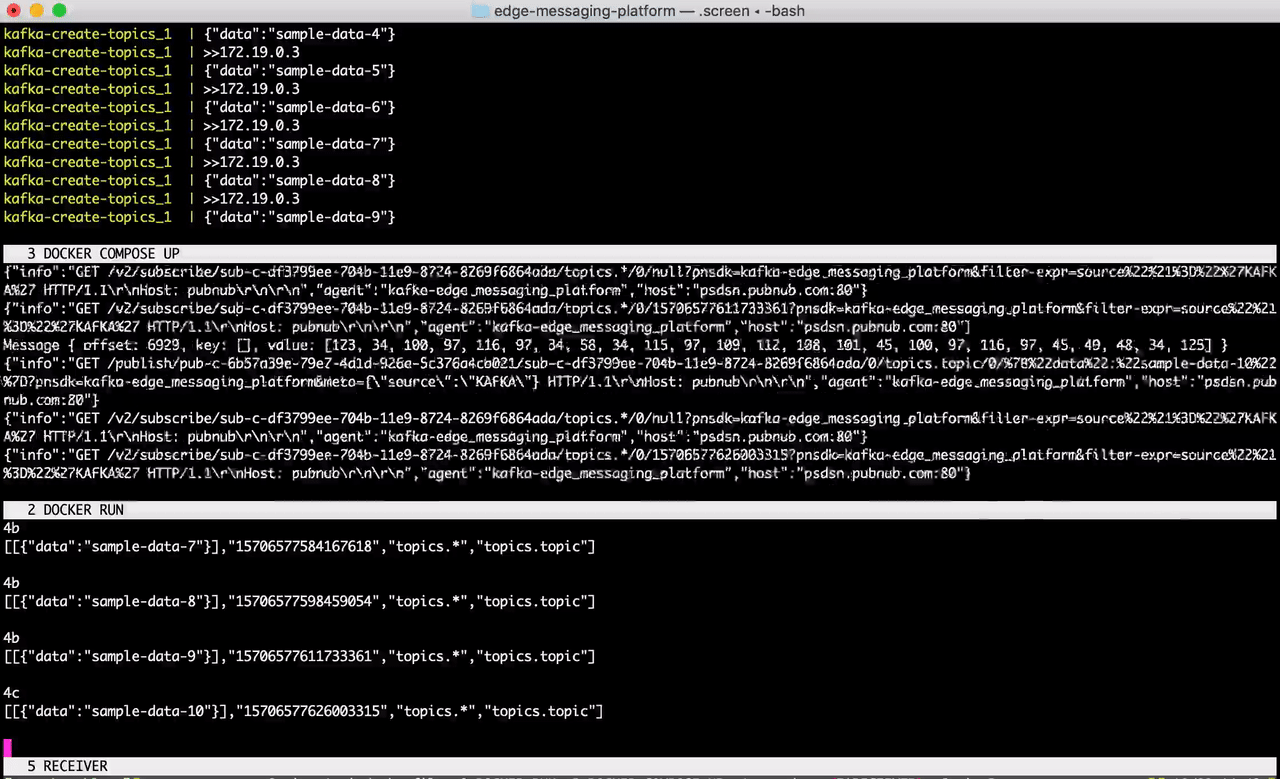
Start the Docker Compose file in a terminal window. This will launch Kafka, ZooKeeper, and a sample feed generator on the topic topic.
Build
git clone git@github.com:pubnub/kafka-bridge.git cd kafka-bridge docker-compose -f kafka/plain/docker-compose.yaml up --force-recreate --remove-orphans
Customize Docker Compose YAML before starting Kafka container
You can modify the environment variables in the ./kafka/plain/docker-compose.yaml file. Inside the Docker Compose YAML the file you’ll find environment variables. These fields can be customized. Add your DNS or IP address there. Most configurations are by environmental variable.
That’s it! If you can’t use Docker Compose, feel free to refer to the alternative setup instructions.
Great! Messages are being simulated on the topic topic as we speak. Now, in a separate terminal session, run the Docker file in step 2.
Step 2: Get up and running in seconds with the PubNub Bridge for Kafka
For security, you will need to get your private API keys from PubNub. The following API keys are for public use and may be rotated. Open a new terminal session and run the following commands.
Run container
cd kafka-bridge
docker build -f kafka/plain/dockerfile -t kafka-bridge .
docker run \
--network=host \
## ~ Replace with your own API Keys ~ https://dashboard.pubnub.com/signup \
-e PUBNUB_PUBLISH_KEY=pub-c-6b57a39e-79e7-4d1d-926e-5c376a4cb021 \
-e PUBNUB_SUBSCRIBE_KEY=sub-c-df3799ee-704b-11e9-8724-8269f6864ada \
-e PUBNUB_SECRET_KEY=sec-c-YWY3NzE0NTYtZTBkMS00YjJjLTgxZDQtN2YzOTY0NWNkNGVk \
## ~ Replace with your own API Keys ~ https://dashboard.pubnub.com/signup \
-e PUBNUB_CHANNEL_ROOT=topics \
-e PUBNUB_CHANNEL="*" \
-e KAFKA_GROUP=test-group \
-e KAFKA_TOPIC=topic \
-e KAFKA_BROKERS=0.0.0.0:9094 \
kafka-bridge
Now your Kafka messages will be securely available to any device on the internet. In the next section, you can receive a stream of your messages.
Step 3: Receive messages on your mobile device from Kafka topics
Terminal session example
The following command is an example of how to receive messages from your Kafka cluster on the internet.
Note that the following sample terminal command opens a lossy sample feed. Use the PubNub SDKs directly to enable durable message delivery.
Open a new terminal session and run the following commands:
export SUBSCRIBE_KEY="sub-c-df3799ee-704b-11e9-8724-8269f6864ada" export TOPICS="topics.*" export HEADERS="HTTP/1.1\r\nHost: pubnub\r\n\r\n" while true; do ( \ printf "GET http://p.pubnub.com/stream/$SUBSCRIBE_KEY/$TOPICS/0/-1 $HEADERS"; sleep 10) | nc p.pubnub.com 80; done
Messages are being delivered from your Kafka cluster directly to your terminal session. This terminal session can be located anywhere on Earth with an active internet connection. You won’t want to use this command directly, as it is only for demonstration purposes. Messages from your Kafka cluster can be received on a mobile and web device. Continue reading to get data onto your target devices using a PubNub SDK.
Send events from Kafka to mobile application
Messages from your Kafka cluster can be received on a target mobile device. Find the mobile SDKs in the documentation.
Test console output
Open the test console to see messages being received in a browser window.
Scroll down on this page until you see an output element labeled messages on this screen with message logs:
![]()
Send events from mobile application to Kafka
You can send a message from the mobile device and receive it in your Kafka cluster. The following shell command will simulate this:
while true; do \ PUBLISH_KEY="pub-c-6b57a39e-79e7-4d1d-926e-5c376a4cb021" \ SUBSCRIBE_KEY="sub-c-df3799ee-704b-11e9-8724-8269f6864ada" \ CHANNEL="topics.mydevice" \ curl "https://ps.pndsn.com/publish/$PUBLISH_KEY/$SUBSCRIBE_KEY/0/$CHANNEL/0/%22Hello%22"; \ echo; \ sleep 0.5; \ done
This command will simulate a mobile device sending messages to the PubNub Edge where they are copied to your Kafka cluster.
You will see a "Hello" message every half-second.
Kafka: The ideal choice to support event streaming
Sharing event streams between teams requires a broad organization strategy. To securely share streams of events between teams, a centralized event bus must be established and maintained. Most teams have specific goals for accomplishing a business objective. This tends to require a specialized selection of tools and services, which are not shareable between teams due to the non-homogeneous workload requirements.
This is why a broad centralized event streaming platform, such as Kafka, is needed. Granting access to each of these systems requires additional business routing logic and may not even be possible to segment access to specific regions of data. Typically, full access is required and may not be ideal for an organization to share data this way.
The PubNub Bridge for Kafka with Confluent Platform allows your teams to share specific topics of information between teams. This allows teams to collaborate across the corporate organization with data access audit trails to selectively permission event streams.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...