Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Introducing Confluent Platform 5.2
Includes free forever Confluent Platform on a single Apache Kafka® broker, improved Control Center functionality at scale and hybrid cloud streaming
We are very excited to announce the general availability of Confluent Platform 5.2, the event streaming platform built by the original creators of Apache Kafka.
Event streaming has become one of the few foundational technologies that sit at the heart of modern enterprises, redefining how you connect every existing application, while enabling you to build an entirely new category of applications—what we call contextual event-driven applications.
What do we mean by contextual event-driven applications? Well, infrastructure to support event-driven applications has been around for decades; mere messaging is nothing new. The main difference is that Confluent Platform gives you the power to process events as well as store and understand an application’s entire event history at the same time, adding critically important historical context to real-time event streaming.
Think of a retailer that builds an application that matches real-time online transactions with inventory information stored in a database to ensure the availability of purchased items. The event streaming platform is a new class of data infrastructure designed to enable the kinds of applications that organizations in every industry and across the globe are building now.
At Confluent, we are devoted to delivering an enterprise-ready event streaming platform that enables you to realize this technological shift at scale in an increasingly hybrid and multi-cloud landscape.
Confluent Platform 5.2 represents a significant milestone in our efforts across three key dimensions:
- It allows you to use the entire Confluent Platform free forever in single-broker Kafka clusters, so you are freer than ever to start building new event streaming applications right away. We are also bringing librdkafka 1.0 in order to bring our C/C++, Python, Go and .NET clients closer to parity with the Java client.
- It adds critical enhancements to Confluent Control Center that will help you meet your event streaming SLAs in distributed Apache Kafka environments at greater scale.
- With our latest version of Confluent Replicator, you can now seamlessly stream events across on-prem and public cloud deployments.
Accelerate the development of contextual event-driven applications
The true value of the event streaming platform is the new generation of contextual event-driven applications that you can build. We want to enable every developer to build on Apache Kafka using the powerful capabilities of Confluent Platform, and we’re doing this in a major way with the introduction of a new license just for developers.
Confluent Platform now available “free forever” on a single Kafka broker
At Confluent, we believe in the power of free and open software. Several components of Confluent Platform have always been available for free, such as KSQL, Schema Registry and REST Proxy, which are licensed under our Confluent Community License.
Historically, Control Center, Replicator, enterprise security features, and the other commercial features of Confluent Platform have had a free thirty-day Evaluation license. Often, though, that’s not long enough for you as a developer to experiment freely and figure out how you can use the entire platform to solve the next generation of problems you are facing.
This is why we’re excited to introduce the newly available Developer License, which allows you to run all commercial features of Confluent Platform for free on single-broker Kafka clusters. This means you now have access, without any time constraints, to tools such as Control Center, Replicator, security plugins for LDAP and connectors for systems, such as IBM MQ, Apache Cassandra™ and Google Cloud Storage. (This is great news in regard to our commercial features, but remember that you already had this benefit for Apache Kafka and our community features, which you can always use for free on an unlimited number of Kafka brokers.)

In recent releases, we have made major enhancements to Control Center directly aimed at application developers. With unrestricted access to Control Center, you will be able to browse messages within topics, view and edit schemas, add and remove connectors and write KSQL queries using the GUI, among other things. We think having access to this advanced set of capabilities long before you’re ready to deploy any code will help you build new contextual event-driven applications faster.
librdkafka is now 1.0, and so are the Confluent clients!
Confluent Platform 5.2 proudly introduces librdkafka 1.0. This is a big milestone, because it brings this popular client library closer to parity with the Java client for Kafka. Here are the high points:
- Idempotent producer: Provides exactly once producer functionality and guaranteed ordering of messages.
- Sparse connections: Clients now connect to a single bootstrap server to acquire metadata and only communicate with the brokers they need to, greatly reducing the number of connections between clients and brokers, and helping mitigate connection storms.
- ZSTD compression: Provides support for the real-time compression algorithm maintained by Facebook. (You may have thought lossless compression was a solved problem, but this new scheme is a meaningful improvement.)
- max.poll.interval.ms (KIP-62): Allows users to set the session timeout significantly lower to detect process crashes faster. Applications are required to call rd_kafka_consumer_poll()/rd_kafka_poll() at least every max.poll.interval.ms or else the consumer will automatically leave the group and lose its assigned partitions. With great timeout detection latency comes great responsibility.
- librdkafka version 1.0.0: API (C and C++) and ABI (C) compatible with older versions, but note changes to configs (e.g., acks=all is now default).
- Additional enhancements and bug fixes, all carefully documented in the release notes.
Because our Confluent clients for Python, Go and .NET are all based on librdkafka, each of them includes these improvements by virtue of this upgrade. On top of this, we’ve completed a major overhaul of the popular .NET client. The new API is significantly easier to use, more idiomatic and extensible. Some highlights:
- It includes an AdminClient for working with topics, partitions and broker configuration
- It provides more idiomatic and straightforward handling of errors
- It is a powerful serialization API with explicit support for both async and sync serializers
- Clients are now constructed using static configuration classes and the builder pattern
- Once again, make sure to take a look at the full release notes
Now that we have equipped you with new ways to produce and consume messages, let’s talk about new ways to transform those messages using the power of stream processing and the enhancements we made to KSQL.
KSQL adds new query expressions and gets GUI enhancements
Stream processing is a key ingredient to building contextual event-driven applications that are capable of combining historical and real-time data. KSQL simplifies stream processing on Kafka by giving you an interactive SQL interface in place of a Java API. In Confluent Platform 5.2, KSQL has grown some features that we think you’ll find useful.
One major advancement is that KSQL now offers new and enhanced query expressions:
- CASE: An operator that executes pieces of a query based on a conditional expression, similar to if/else (you may be used to this in ANSI SQL), which you can read about among other improvements in KSQL: What’s New in 5.2.
- BETWEEN: A simpler and more expressive way to define a range expression.
- SPLIT: A built-in function for splitting a string into an array of substrings based on a delimiter.
- PRINT/LIMIT: Both expressions already existed independently, but now PRINT supports LIMIT, so you can dump the contents of large-cardinality streams without an eternity of scrolling.
- GROUP BY: This has always been with us, but it now works with fields in structs, arithmetic results, functions, string concatenations and literals.
--Assign buckets to data based on the range of values
CREATE STREAM ORDERS_BUCKETED AS SELECT ORDER_ID, CASE WHEN ORDER_TOTAL_USD < 5 THEN 'Small' WHEN ORDER_TOTAL_USD BETWEEN 5 AND 7 THEN 'Medium' ELSE 'Large' END AS ORDER_SIZE FROM ORDERS;
KSQL CASE expression in action
Control Center continues to grow as a development tool by adding KSQL-focused UI enhancements. Some of the changes include:
- Feed pause and resume
- Card and table formats
- Clearer query status
- Improved error messaging
- Output metadata
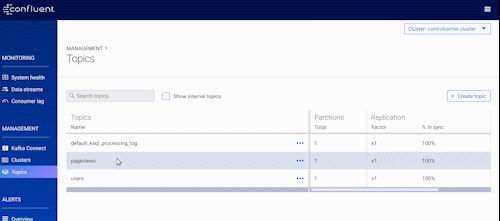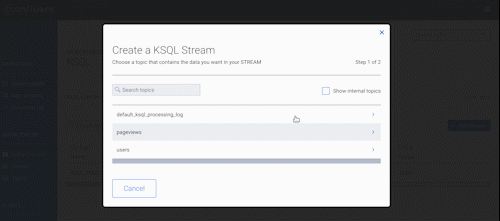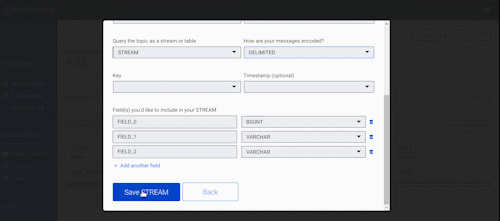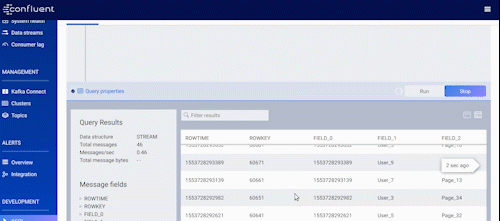
Speaking of Control Center, we added many more new features designed to help those of you running Kafka in production at decent scale. Let’s take a look at what those new features are.
Meet event streaming SLAs at larger scale with Confluent Control Center
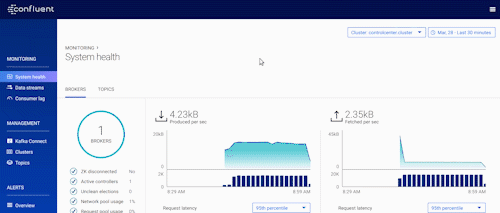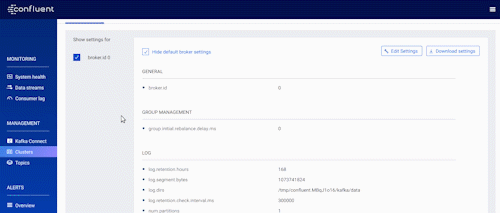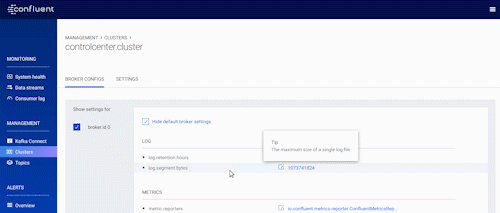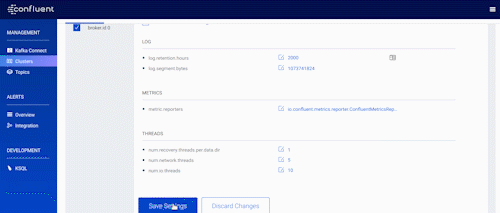
Meeting SLAs for your event streams can be challenging as your Kafka environment expands in size and supports a greater number of applications and users. Having a tool like Control Center that allows you to look inside Kafka to understand and control the state of your messages and your infrastructure becomes critical. The latest version of Control Center gives you greater control over certain components of the Kafka architecture, such as Schema Registry, and a set of enhancements to oversee even more complex Kafka deployments.
Schema management
Prior to 5.2, you could only view your schemas in the Control Center GUI. Confluent Platform 5.2 brings much greater control, now allowing you to create and edit schemas, validate your schemas against the compatibility policy and make changes to the compatibility policy itself.
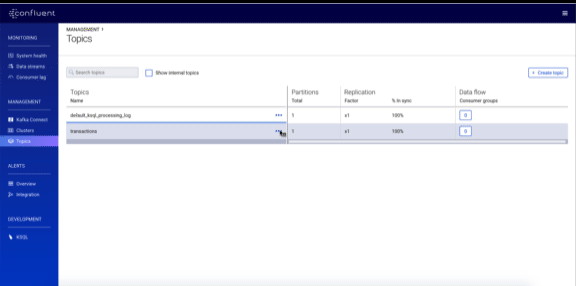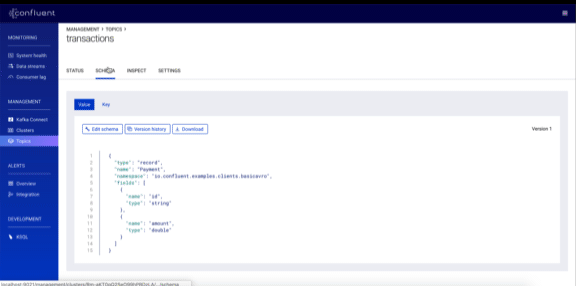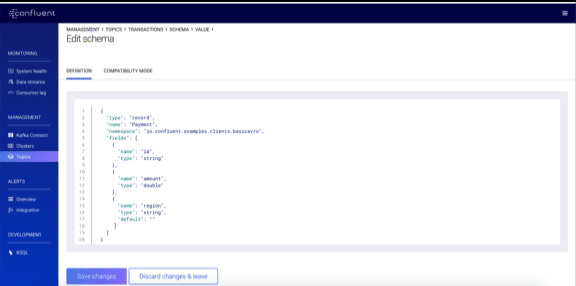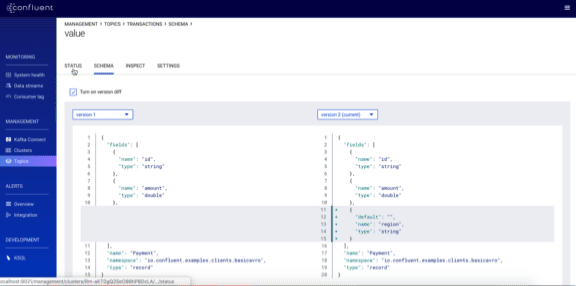
You can read more about the Control Center 5.2 enhancements in Dawn of Kafka DevOps: Managing and Evolving Schemas with Confluent Control Center.
Dynamic broker configuration
Before this release, Control Center allowed you to view broker configurations across multiple Kafka clusters. This time, we’ve added greater control by enabling you not only to view but also to make changes to broker configurations dynamically in instances where the broker doesn’t require a complete restart.
Dawn of Kafka DevOps: Managing Kafka Clusters at Scale with Confluent Control Center dives into this in more detail.
Multi-cluster Kafka Connect and KSQL
Control Center now supports multiple Kafka Connect and KSQL clusters talking to the same Kafka cluster. This means you can run, monitor and manage connectors on more than one Connect cluster, and run queries on more than one KSQL cluster, all within the same Control Center UI. This makes Control Center even more useful for managing and building with Kafka at scale.
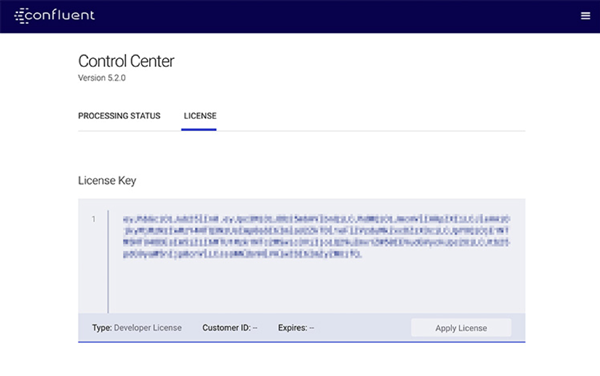
License management
Broadening its scope as the go-to graphical tool for Confluent Platform, Control Center is now capable of delivering shared services across the platform via license management. This new capability takes care of license checking, license submission, pending expiration alerts (three months out, one month out, weekly for the last month, daily for the last week) and expired license notices. If you’re in charge of a production cluster, this makes managing the subscription license easier across every component of the platform.
Improved scalability of up to 40K topic partitions
Because we insist on making Control Center the ideal tool for understanding enterprise streaming workloads, we’ve continued making enhancements to its scalability. Control Center now manages up to 120,000 individual partition replicas, which translates to 40,000 topic partitions assuming a standard replication factor of three and a typical partitioning scheme of eight partitions per topic. If topics have a smaller replication factor, then Control Center could scale to greater than 40,000 partitions.
So far, we have covered all the new capabilities of Confluent Platform 5.2 that benefit those of you running your own Kafka deployments. However, there is a growing number of you that are interested in what a fully managed service like Confluent Cloud can provide. Let’s shift gears and discuss hybrid event streaming leveraging Confluent Cloud.
Enable event streaming across hybrid environments
We live in an increasingly hybrid and multi-cloud world. You want to use the best services available from different cloud providers, and your CIO likely wants to avoid cloud vendor lock-in.
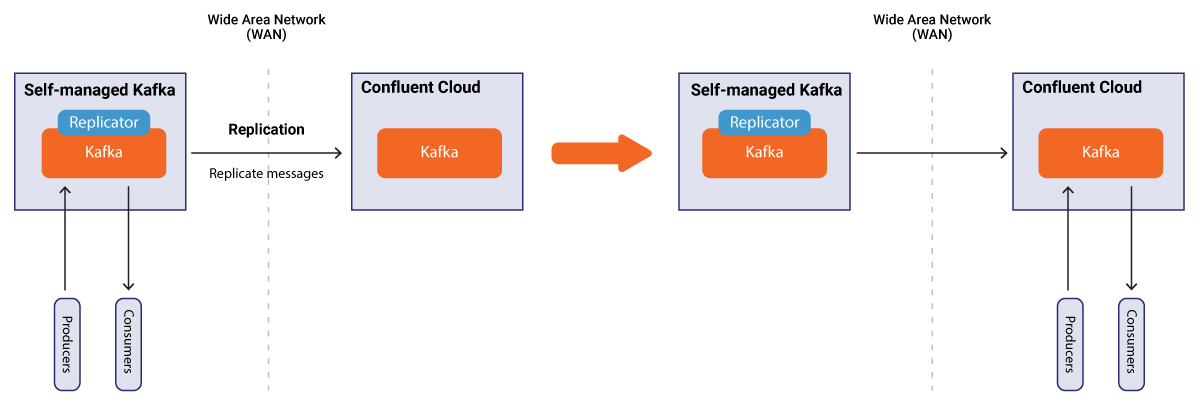
Confluent offers the only hybrid event streaming platform in the industry via Confluent Platform and Confluent Cloud. Using Confluent Replicator, you can seamlessly move your event streams from your on-prem deployment to our fully managed Apache Kafka service running in the major public clouds.
Replicator supports schema migration to Confluent Cloud
In Confluent Platform 5.2, Confluent Replicator now supports migration of schemas from a self-managed, on-prem Schema Registry to a fully managed Schema Registry in Confluent Cloud. Specifically, Replicator supports the following two scenarios:
- Continuous migration: You can use your self-managed Schema Registry as a primary and Confluent Cloud Schema Registry as a secondary. New schemas will be registered directly to the self-managed Schema Registry, and Replicator will continuously copy schemas from it to the Confluent Cloud Schema Registry, which should be set to IMPORT mode.
- One-time migration: This is great if you intend to migrate your existing self-managed Schema Registry to Confluent Cloud Schema Registry as a primary. All new schemas are registered to Confluent Cloud Schema Registry. In this scenario, there is no migration from Confluent Cloud Schema Registry back to the self-managed Schema Registry.
This new capability makes seamless hybrid streaming possible, because it eliminates the need to recreate your schemas in the cloud after a migration. It also gives you the option to fully offload the operation of your Schema Registry to the expert operators who run Confluent Cloud.
New in Apache Kafka 2.2.0
Like all of our releases, Confluent Platform 5.2 is built on the most recent version of Apache Kafka. Confluent Platform 5.2 includes Apache Kafka 2.2.0, which contains a number of new features, performance improvements and bug fixes, including:
- More use of AdminClient in commands: kafka-preferred-replica-election.sh and kafka-topics.sh now use the AdminClient, so no need to pass in --zookeeper! Note that the kafka-preferred-replica-election.sh command is not available in the Confluent Cloud CLI. (KIP-183 and KIP-337)
- Improved the default group ID behavior in KafkaConsumer: Default group.id has been changed from “ “ to null, so that unnecessary or unintentional offset fetches/commits are avoided. (KIP-289)
- Separate controller and data planes: This feature separates controller connections and requests from data plane, which helps ensure controller stability even if the cluster is overloaded due to produce/fetch requests. This feature is disabled by default. (KIP-291)
- Detection of outdated control requests and bounced brokers: Kafka now detects outdated control requests to increase cluster stability when a broker bounces. (KIP-380)
- Introduction of configurable consumer group size limit: This introduces a configurable consumer group size limit that protects the cluster resources from too many consumers joining a consumer group. (KIP-389)
Eighteen new features and configuration changes have been added with 150 resolved bug fixes and improvements. For a full list of changes in this release of Apache Kafka, see the Apache Kafka 2.2.0 release notes.
Get started
We hope you are as pleased as we are with our latest release. With new capabilities like librdkafka 1.0 and our enhanced set of clients, as well as the new expressions added to KSQL, we are giving you more and more of the tools you need to develop a whole new class of applications. We are also making it easier to manage larger and more complex Kafka deployments with Control Center, and we are enabling hybrid event streaming with the ability to replicate your Schema Registry to Confluent Cloud.
Best of all, you can now run all of Confluent Platform free with our new Developer License. Download Confluent Platform today and start using our advanced commercial features for free on single Kafka broker, or try them free for 30 days on as many brokers as you need.
If you want to learn more about the new features in Confluent Platform 5.2, read the release notes.
As always, we are happy to hear your feedback. Please post your questions and suggestions to the public Confluent Platform mailing list, join our community Slack channel or contact us directly! We can’t make this the world’s best event streaming platform without you.
This post is not the work of one single person, so many thanks to Neha Narkhede, Tim Berglund, Gaetan Castelein, Victoria Yu, Michael Drogalis, Raj Jain, Guozhang Wang, Nathan Nam, Addison Huddy, Yeva Byzek, Erica Knowlton Bennett and Matt Howlett for all their contributions.
Note: “Free forever” refers to use under the Developer License as described in the Confluent License Agreement.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...