Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Introducing Confluent Platform 6.1
We are pleased to announce the release of Confluent Platform 6.1. With this release, we are further simplifying management tasks for Apache Kafka® operators and providing even higher availability for enterprises who use Kafka as their central nervous system and data backbone for business-critical applications. Building on the innovative feature set delivered in Confluent Platform 6.0, this release make enhancements to three categories of features:
- First, we are helping to reduce the risk of downtime in Kafka using automation and continuous deployment. We are simplifying the disaster recovery process for multi-datacenter clusters with Automatic Observer Promotion and minimizing the disruption to event streaming apps when updating data schemas with ksqlDB in-place query upgrades.
- Next, we have made enhancements to simplify and improve Kafka operations and efficiency, while providing a streamlined user experience. We’re making it easier to manage clusters using user-friendly cluster names with Cluster Registry integration into Control Center and simplifying the development of event streaming apps with ksqlDB multi-key pull queries.
- Finally, we are improving visibility and control with centralized management by enabling Kafka operators to track the progress of partition rebalances through a new Self-Balancing Clusters Status API.
As with previous Confluent Platform releases, you can always find more details about the features in the release notes or in the video below.
Keep reading to get a high-level overview of what’s included in Confluent Platform 6.1.
Download Confluent Platform 6.1
Reduced downtime
Many enterprises have mission-critical applications that cannot go down, and the events powering those streaming applications need to be available at all times. Unexpected Kafka cluster failures and disruption to streaming data pipelines can incur significant costs and/or lost revenue to a business. Confluent Platform 6.1 achieves higher availability through automation and enables operators to build more reliable data pipelines.
Confluent Platform enhances Kafka reliability with Automatic Observer Promotion for Multi-Region Clusters
In Confluent Platform 5.4, we introduced Multi-Region Clusters (MRC) to deploy a single cluster across multiple datacenters, ensuring higher availability for event streaming applications and dramatically simplifying disaster recovery operations for Kafka. As part of MRC, we also introduced the concept of an asynchronous “observer” replica, which allows individual clusters to stretch across longer distances and enhance their resiliency without sacrificing latency performance.
One established deployment pattern for MRC is to put observer replicas in a backup datacenter, so that when a main datacenter goes offline, the observers can be promoted to the in-sync replica (ISR) list. Clients then automatically fail over to the newly promoted observer, which greatly reduces downtime and its associated costs to the business. It also saves many engineering months spent developing failover logic for each event streaming application. Prior to Confluent Platform 6.1, however, operators had to manually intervene to promote an observer or had to develop and maintain custom tooling to perform the task. This was not only inconvenient, but it could also result in human error, longer recovery times, and increased business disruption.
With the release of Confluent Platform 6.1, we’re introducing Automatic Observer Promotion to automate that entire process. This functionality quickly restores application operations when a datacenter goes down, without manual intervention or custom tooling. When the original brokers come back online, the observer replicas will automatically be demoted, restoring the cluster to steady state. Throughout the whole process, clients continue to produce to and consume from the appropriate brokers without disruption, enabling your business to continue operating resiliently as usual. It’s also very simple to configure, whether for just one topic or cluster-wide.
Here is an example scenario, where producers write to two main datacenters, and observers are placed in the backup datacenter:
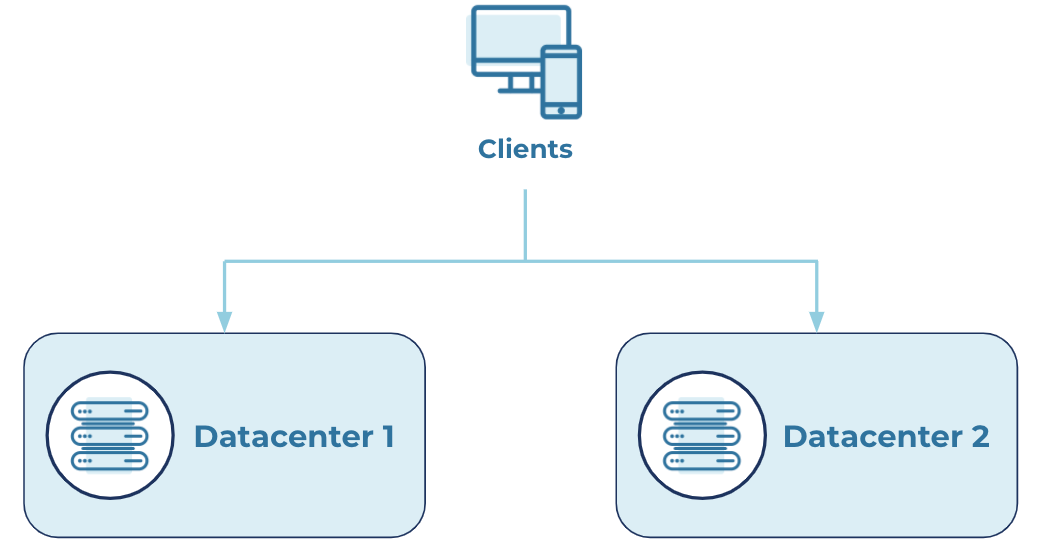
Steady state
When one of the main datacenters fails, Automatic Observer Promotion moves Observers into the ISR list. This quickly satisfies the minimum ISR requirement and restores application operation.
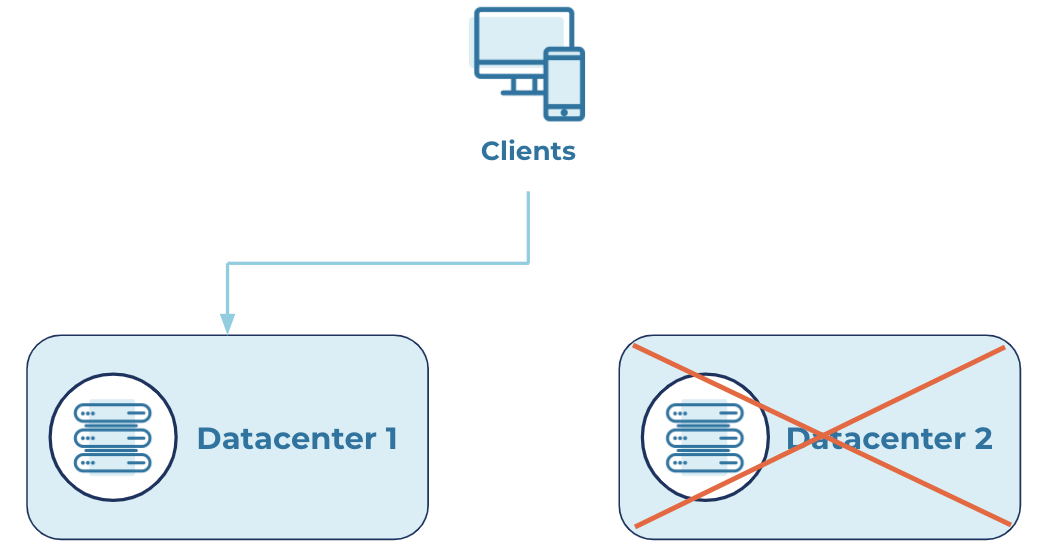
Failure state
With Multi-Region Clusters (MRC) and Automatic Observer Promotion, your clusters can tolerate broker failures with minimal downtime, thus enabling you to maintain very high availability and meet your recovery time objectives (RTOs).
In-place ksqlDB query upgrades help minimize disruption to event streaming applications
Once event streaming applications are in production, it’s common for those apps to need data schema and query logic adjustments to meet new business requirements. Previously, changing query logic or adding new columns to a stream or table schema would result in the streaming application going offline while you perform the upgrade, which could result in downtime costs for the business.
Confluent Platform 6.1 now supports the ability to evolve production queries as business requirements change over time by introducing in-place upgrades of ksqlDB production queries. With this functionality, enterprises can iterate and make improvements to their mission-critical applications without needing to sacrifice their availability, thus minimizing business disruption.
As is standard for ksqlDB, the syntax for an in-place upgrade is quite simple. Using the CREATE OR REPLACE statement, you can easily redefine the schema for a stream or table to incorporate a newly required column. If the stream or table has many columns, you can also use the ALTER statement to add a single column and define its type without needing to do the same for the rest of the existing schema. Here’s an example of the two options:
-- Original stream CREATE STREAM s (x INTEGER, y INTEGER) WITH (...); -- Add a column ALTER STREAM s ADD COLUMN z INTEGER; -- Note that CREATE OR REPLACE may also be used to change a schema: CREATE OR REPLACE STREAM s (x INTEGER, y INTEGER, z INTEGER) WITH (...);
In a similar manner, general query logic can be updated within some constraints.
In-place query upgrades help developers build reliable data pipelines with minimal disruption to streaming applications using the principles of continuous deployment. This enables developers to react quickly to changing business requirements.
Simpler operations
Kafka is a robust, distributed data system, designed to maintain optimal performance even as you reach massive scale. However, building event streaming applications on top of Kafka, along with properly configuring and operating the cluster, can often be complex. Confluent Platform 6.1 makes the event streaming platform even easier to use with enhanced developer tooling and simpler configuration, offering our best user experience yet.
ksqlDB further streamlines the development of event streaming apps with multi-key pull queries
ksqlDB’s pull queries are a form of query that enable you to fetch the current state of data from a materialized view, similar to a query against a traditional database. Because these materialized views are read optimized and incrementally updated as new events occur, pull queries run with low latency and are a great match for point-in-time lookups of information.
Until now, pull queries have been limited to lookups using a single key in the WHERE clause, which restricted how easily you could access your data. One workaround consisted of issuing multiple pull queries (one per key), but this was a cumbersome approach that did not scale efficiently, especially if you needed to access many rows of data.
With Confluent Platform 6.1, we’ve expanded support to include the IN predicate, which allows lookups using multiple keys. This condenses the number of requests that you need to send to look up a series of rows.
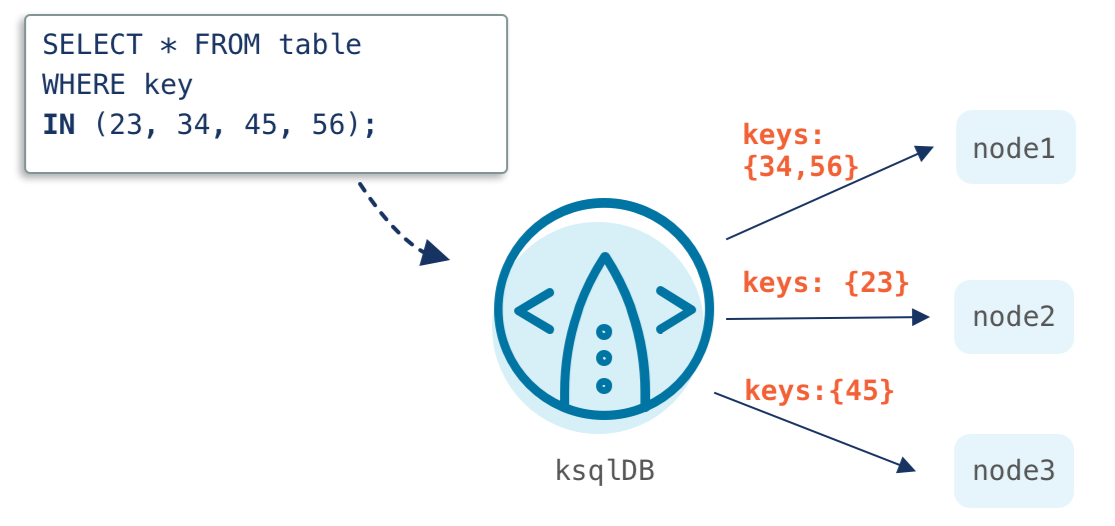
By allowing for more flexible lookups with ksqlDB, multi-key pull queries help further streamline the development of event streaming applications that provide real-time, personalized experiences to your customers and immediate insights to your business.
Cluster Registry integration with Control Center enables the use of cluster-friendly names across Confluent Platform
Introduced in Confluent Platform 6.0, Cluster Registry allows you to register clusters with user-defined names. This makes it much simpler to configure, manage, and debug clusters by using a memory-friendly name rather than the Kafka GUID (globally unique identifier) like LRx92c9yQ+ws786HYosuBn. However, this feature was previously not available through Confluent Control Center, which operators want to leverage as their one-stop solution for managing and monitoring Confluent Platform.
With Confluent Platform 6.1, we’re tightening the integration between Cluster Registry and Control Center. You can now easily set the user-friendly name in the GUI, and it will then migrate this name to Cluster Registry.
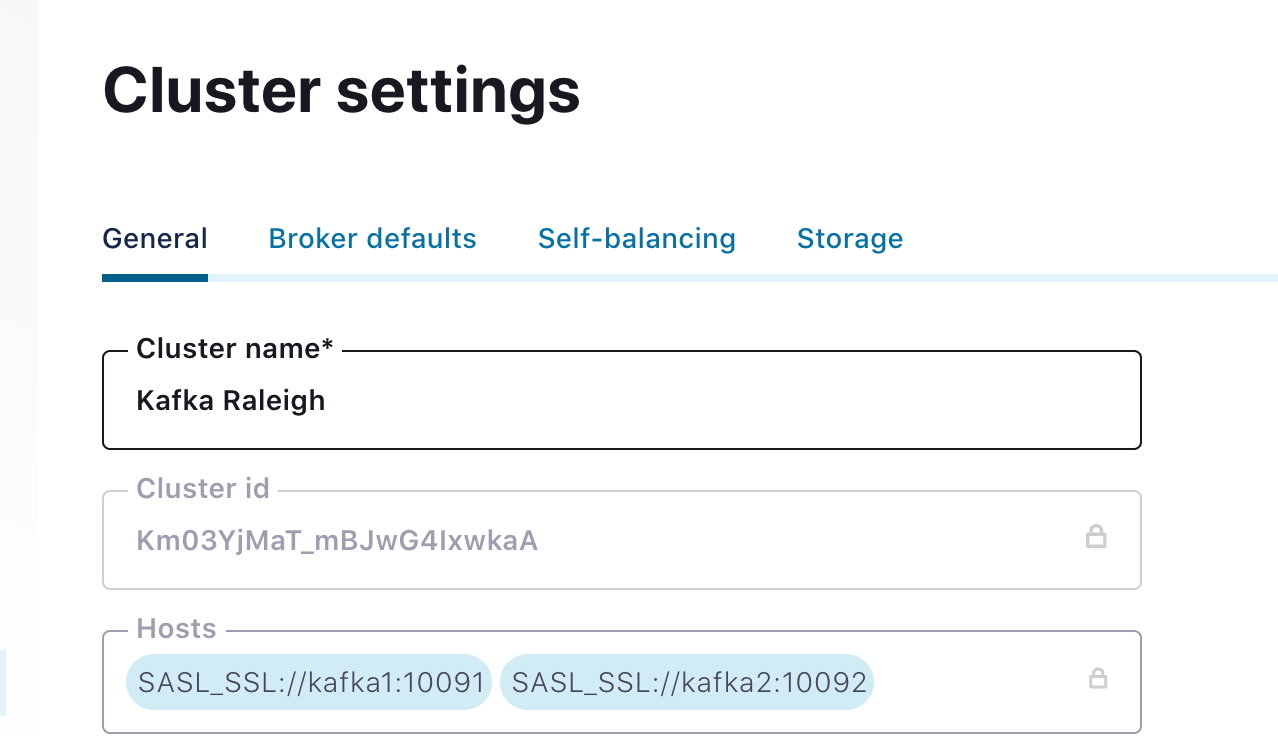
Once you register the friendly name, you’ll see it used throughout Control Center. For example, when you are setting RBAC role bindings, you will now see the user-friendly name instead of the cluster GUID.
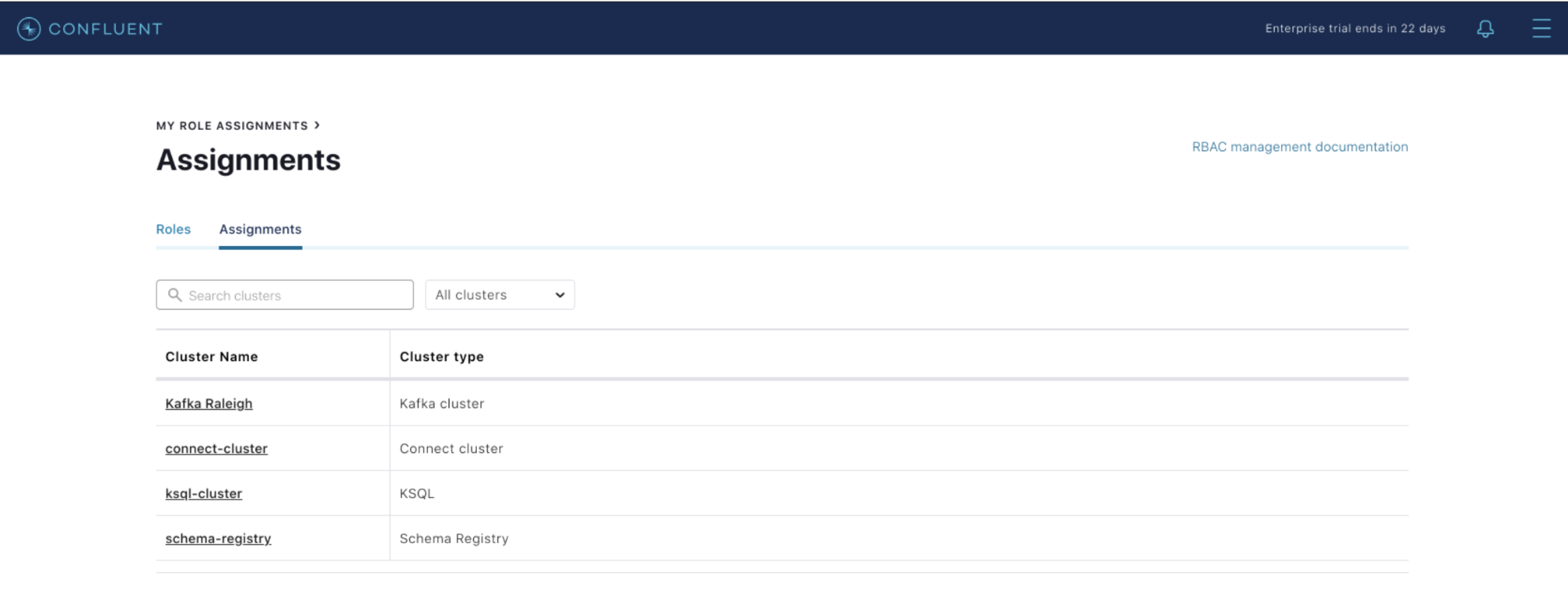
The integration between Cluster Registry and Control Center enables centralized, consistent, and easy-to-remember cluster names, which can be accessed across the platform. This further reduces Kafka’s operational burden and provides a more intuitive management experience for our users.
Improved visibility and control
Kafka can be difficult to manage and monitor as it scales across the enterprise. With the latest release, we’re delivering enhancements that further empower users to centrally manage operations, gain visibility, and control key components of the platform.
Self-Balancing Clusters adds a new Status API to easily track the progress of partition rebalances
Also introduced in Confluent Platform 6.0, Self-Balancing Clusters help automate partition rebalances to optimize Kafka’s throughput, accelerate broker scaling, and reduce the operational burden of managing a large cluster. Moreover, Self-Balancing Clusters ensure that partition rebalances are completed quickly and without any risk of human error. Up until now, however, it has been difficult to track the progress of these rebalancing operations and whether rebalances were executing at any one point in time.
Confluent Platform 6.1 introduces a Status API that queries the status of rebalancing operations, such as adding or decommissioning brokers. This vastly improves user visibility and helps inform operators on whether these operations are executing successfully, slowing down due to metrics collection, or have failed or restarted. The API exposes the broker addition/removal state, and the progress of the rebalance can be monitored within Control Center using a new Status UI:
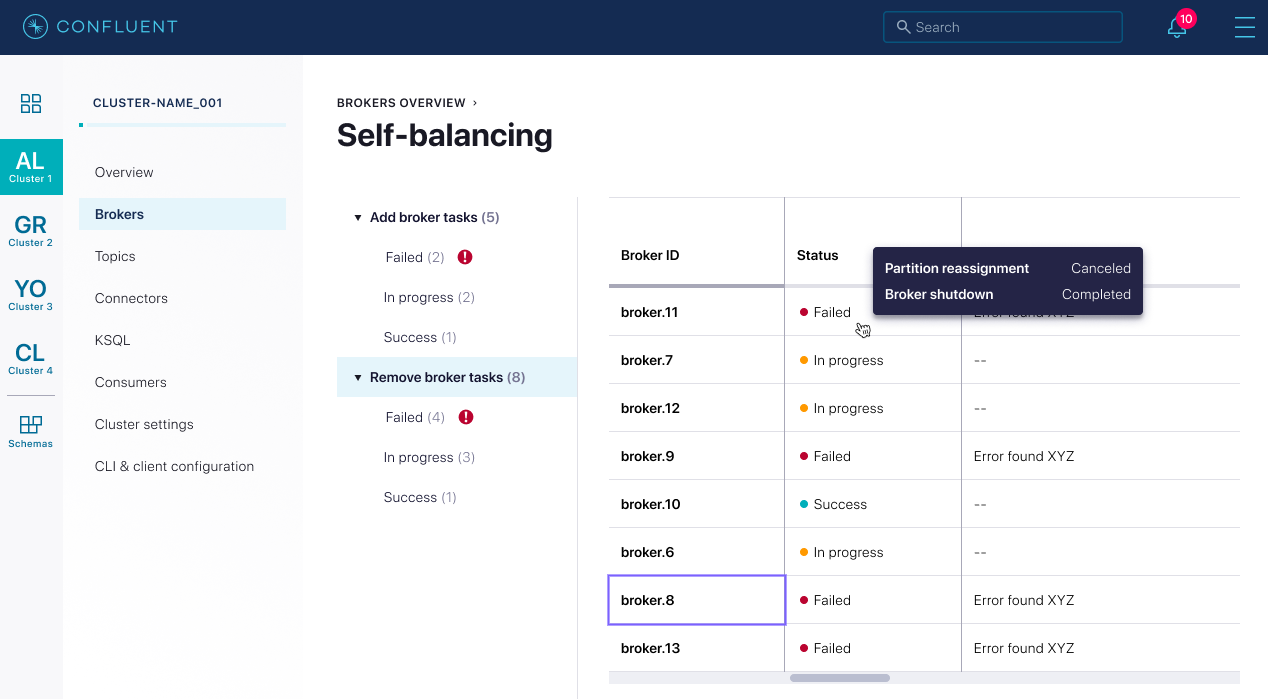
The new Status UI removes the need to leverage the Metrics API to gain visibility into how Self-Balancing Clusters are operating. Now you can easily track rebalances, giving you better control over your clusters and ensuring their healthy operations for your mission-critical applications.
Support for Apache Kafka 2.7
Following the standard for every Confluent release, Confluent Platform 6.1 is built on the most recent version of Kafka, in this case version 2.7. Kafka 2.7 continues to make steady progress toward the task of replacing ZooKeeper in Kafka with KIP-497, which adds a new inter-broker API for altering the ISR, and also provides the addition of the Core Raft Implementation as part of KIP-595.
For details about Apache Kafka 2.7, please read the blog post by Bill Bejeck.
Want to learn more?
Check out Tim Berglund’s video or podcast for an overview of what’s new in Confluent Platform 6.1, and download Confluent Platform 6.1 today to get started with a complete event streaming platform built by the original creators of Apache Kafka.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...