Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
June Preview Release: Packing Confluent Platform with the Features You Requested!
We are very excited to announce Confluent Platform June 2018 Preview. This is our most feature-packed preview release for Confluent Platform since we started doing our monthly preview releases in April 2018.
Read on to learn more, and remember to share your feedback to help improve the Apache Kafka ecosystem. You can do that by visiting the Confluent Community Slack channel (particularly the #ksql and #control-center channels) or by contributing to the KSQL project on GitHub, where you can file issues, submit pull requests, and contribute to discussions.
Confluent Control Center
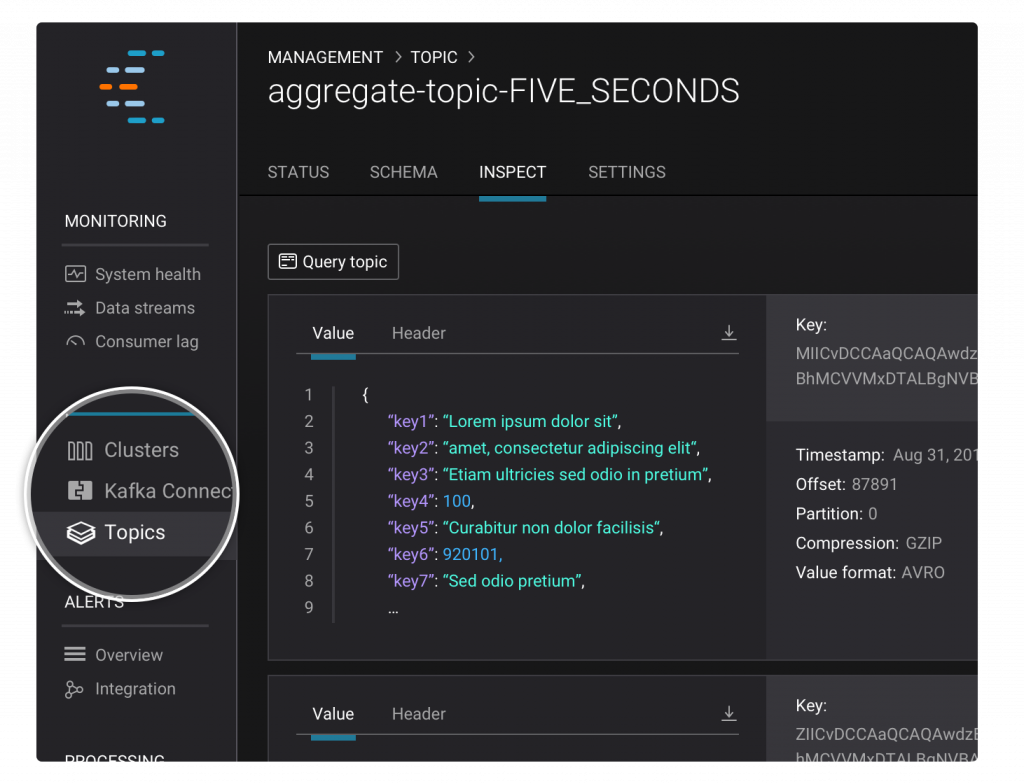
Confluent Schema Registry Support for Topic Inspection
Confluent Control Center’s topic inspection feature already supports JSON and string message formats, but starting with this release, it will have full support for Avro data through the Confluent Schema Registry.
Schema Registry, as we all should know, is a component of Confluent Platform that stores a versioned history of all schemas and works with clients to support predictable schema evolution. To configure Schema Registry in Control Center, simply add confluent.controlcenter.schema.registry.url=<your_schema_registry_server> in control-center.properties file before starting up the application. The message viewer in the topic inspection tab will automatically detect and deserialize Avro records.
Feature Access Control
In this release, we’re also introducing feature access toggles within Confluent Control Center for KSQL, Topic Inspection, and Schema Registry. In many deployments, the end users of Control Center are not allowed to view records in topics for security and compliance reasons. In order to allow admins to control application-wide access to features that reveal topic data in Control Center, we added the option to control access at start-up time. When you restrict access to a feature, Control Center’s UI will reflect this change, and users cannot circumvent these protections in any way.
To enable/disable a feature, change the following configs in the Control Center properties file before starting up:
confluent.controlcenter.ksql.enable=[true|false]
confluent.controlcenter.schema.registry.enable=[true|false]
confluent.controlcenter.topic.inspection.enable=[true|false]
KSQL
Working with Nested Data
One of the most requested enhancements for KSQL has been support for complex nested data types. Starting with the June preview release, you can now declare streams and tables with columns using a STRUCT data type in your CREATE STREAM and CREATE TABLE statements, and then access the internal fields of these columns in your SELECT queries as you do in any other expression. STRUCT support is available for both JSON and Avro data formats. Nested fields in the STRUCT can be any valid type in KSQL, including STRUCT, ARRAY and MAP. For instance, you can have a column that is an ARRAY of STRUCTs, where one of the fields in the STRUCT is a MAP. This means KSQL now supports querying data with many nested levels.
The following is an example of declaring an ORDERS stream, where the ADDRESS column has a STRUCT type with nested fields for CITY, STATE, and ZIPCODE:
You can refer to fields in a STRUCT using the `->` operator:
Beyond SQL with User Defined Functions
Another highly requested feature for KSQL has been the ability to define your own functions that go beyond what’s provided by KSQL out of the box. User Defined Functions (UDFs) and User Defined Aggregate Functions (UDAFs) open the door for many novel use cases where you need to perform custom computations over your data. UDFs take one input row to produce one output row (e.g., ABS and SUBSTRING) whereas UDAFs take n input rows to produce one output row (e.g., SUM, MAX, COUNT).
Using the new UDF and UDAF features,you can define custom computations and make them available to your KSQL queries in case the built-in scalar functions or the built-in aggregation functions are not sufficient.
For now, UDF(A)Fs need to be implemented in Java. You simply write the function code and mark the classes with @Udf or @UdafFactory annotations. To make the UDF(A)Fs available to KSQL, you must create an uberjar of the UDF(A)Fs code including any transitive dependencies, and then place the jar file in the `ext/` folder of a KSQL Server. To better secure your KSQL deployment environment when using UDF(A)Fs you can also provide an optional blacklisting configuration that will prevent the use of certain Java classes and packages such as `java.io.*`. Finally, you can use the SHOW FUNCTIONS statement to get a listing of all available functions including UDFs and UDAFs.
Here is an example UDF that returns the length of a string:
Here is an example of calling the `STRING_LENGTH` function:
Even more interesting is the ability to bring your own custom aggregation functions. Here we define a UDAF for computing the sum of string lengths:
This UDAF can then be used in your KSQL queries:
Stream-Stream and Table-Table Joins
Beyond the existing Stream-Table joins, the June preview release introduces Stream-Stream and Table-Table joins. For each of these joins, KSQL supports inner, full outer, and left join types. This means KSQL now covers all of the available join operations in Kafka Streams.
A Stream-Stream join enables KSQL users to join two streams based on the desired message key within a given join window. Consider the following scenario where we have two streams, ORDERS and SHIPMENTS. Assuming that an order is late if it is shipped more than 2 hours after the order was placed, we can create a new stream for the late orders by joining the two streams and filtering the orders that were not shipped in the given time window. The following query creates the stream of late orders:
The above query will match every shipment row with the order rows that are within the 2-hour window. If there is no match, the right-hand side of the join result will be NULL, indicating that the given order was not shipped within the expected time. Note that we used the `WITHIN` keyword in the Stream-Stream join to specify the join window.
Where to go from here
Try out the new Confluent Platform June 2018 Preview release and share your feedback! Here’s what you can do to get started:
- Download Confluent Platform June 2018 preview release.
- Check out the Docker images for KSQL Server and KSQL CLI.
- Visit the Confluent Community Slack channel to ask questions or share feedback. To discuss KSQL, visit the #ksql channel. For Control Center, visit the #control-center channel.
- If you are interested in contributing to KSQL, visit the KSQL project on GitHub. Feel free to file issues, submit pull requests, and contribute to discussions there.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...