Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Announcing ksqlDB 0.14.0
We’re pleased to announce ksqlDB 0.14, one of our most significant releases of the year. This version includes expanded query support over materialized views, incremental schema alteration, variable substitution, additional key formats, and more. We’ll step through the most notable changes, but see the changelog for the complete list.
Multiple key lookups in pull queries
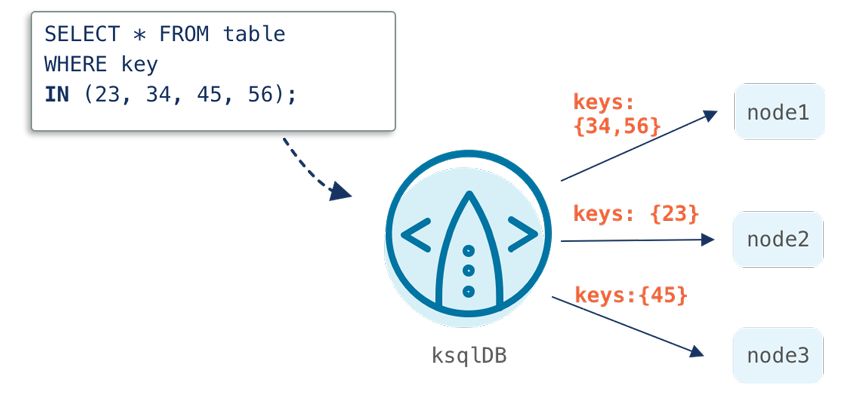
ksqlDB’s pull queries allow you to fetch the current state of a materialized view. Until now, pull queries have been limited to lookups using a single key in the WHERE clause. We’ve expanded support to include the IN predicate, which allows lookups using multiple keys.
SELECT * FROM table WHERE key IN (23, 34, 45, 56, 67, 78);
Alter the schema of streams and tables
The CREATE OR REPLACE syntax for query upgrades was added in ksqlDB 0.12. It allows you to add new columns to a stream or table schema, upgrading it in place. However, CREATE OR REPLACE requires you to specify the full, original schema including the newly added column. This can be tedious if the stream or table has many columns and you just want to add one column.
In ksqlDB 0.14, the ALTER syntax allows you to add one or more columns without having to provide the full, existing schema. Currently, the ALTER command is only supported for streams and tables created using DDL statements (CREATE ... WITH). Streams and tables created with CREATE ... AS SELECT cannot be altered as the schema is defined in the SELECT clause.
Here is the syntax for the ALTER command:
ALTER [TABLE | STREAM] ] ...];
alter_option: ADD [COLUMN]
Here is an example that adds two new columns to an existing stream:
CREATE STREAM s1 (id INT, v0 INT) WITH (KAFKA_TOPIC='s1', VALUE_FORMAT='avro');
ALTER STREAM s1 ADD COLUMN v2 INT, ADD COLUMN v3 INT;
SQL variable substitution
You can now define variables in a CLI session and use those variables in all SQL statements. These variables can be used in your SQL scripts, which you may want to execute with specific settings (topic names, formats, etc.), allowing you to easily test your SQL script behavior in different environments (CI/CD, QA clusters, dev/prod environments, etc).
Below is an example that defines a variable for the VALUE_FORMAT:
DEFINE format = 'json';
CREATE STREAM myStream (id INT) with (KAFKA_TOPIC='aTopic', VALUE_FORMAT='${format}');
The above statement will create a stream with VALUE_FORMAT JSON.
To learn more about variable substitution, visit the developer guide.
New key formats
ksqlDB now supports DELIMITED and JSON key formats in addition to the KAFKA format that has been the default until now. Key formats may be specified using the KEY_FORMAT property in the WITH clause. You can also use the FORMAT property to set both the key and value formats together. A future release will support Schema Registry integrated key formats, including AVRO and JSON_SR as well as non-primitive key types, such as arrays, maps, and structs.
For example, you can create a stream with KEY_FORMAT JSON like so:
CREATE STREAM s1 (id int key, v0 int, v1 int) WITH (KAFKA_TOPIC='s1', KEY_FORMAT ='json', VALUE_FORMAT='json', PARTITIONS=1);
You can verify the formats with the following:
ksql> DESCRIBE EXTENDED s1;
Name : S1 Type : STREAM Timestamp field : Not set - using Key format : JSON Value format : JSON Kafka topic : s1 (partitions: 1, replication: 1) Statement : create stream s1 (id int key, v0 int, v1 int) with (kafka_topic='s1', key_format='json', value_format='json', partitions=1);
Field | Type -------------------------------- ID | INTEGER (key) V0 | INTEGER V1 | INTEGER --------------------------------
You can create a stream that uses DELIMITED for both its key and value formats with this:
CREATE STREAM s2 (K BOOLEAN KEY, V INTEGER) WITH (FORMAT='DELIMITED', KAFKA_TOPIC='s2', PARTITIONS=1);
And verify with this:
ksql> DESCRIBE EXTENDED s2;
Name : S2 Type : STREAM Timestamp field : Not set - using Key format : DELIMITED Value format : DELIMITED Kafka topic : s2 (partitions: 1, replication: 1) Statement : CREATE STREAM s2 (K BOOLEAN KEY, V INTEGER) WITH (FORMAT='DELIMITED', KAFKA_TOPIC='s2', PARTITIONS=1);
Field | Type -------------------------------- K | BOOLEAN (key) V | INTEGER --------------------------------
Get started with ksqlDB
ksqlDB 0.14.0 introduces the ability to query multiple keys from materialized views, alter the schema of existing streams and tables, and use richer key formats, to name a few. We hope you check it out!
To get started, try ksqlDB today via the standalone distribution or with Confluent Cloud, and join the #ksqldb Confluent Community Slack channel to get involved with the community.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.