Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Announcing the Confluent Q1 ‘22 Launch
The Confluent Q1 ‘22 Launch is live and packed full of new features that enable businesses to continue innovating quickly with real-time experiences fueled by data in motion. Our quarterly launches provide a single resource to learn about the accelerating number of new features we’re bringing to Confluent Cloud, our cloud-native data streaming platform.
Here’s an overview of everything you’ll find within this blog:
- The Q1 ‘22 Launch summary
- Demo webinar registration
- New feature deep dives:
Simplified real-time data integrations and massive-throughput elasticity with the Confluent Q1 ‘22 Launch
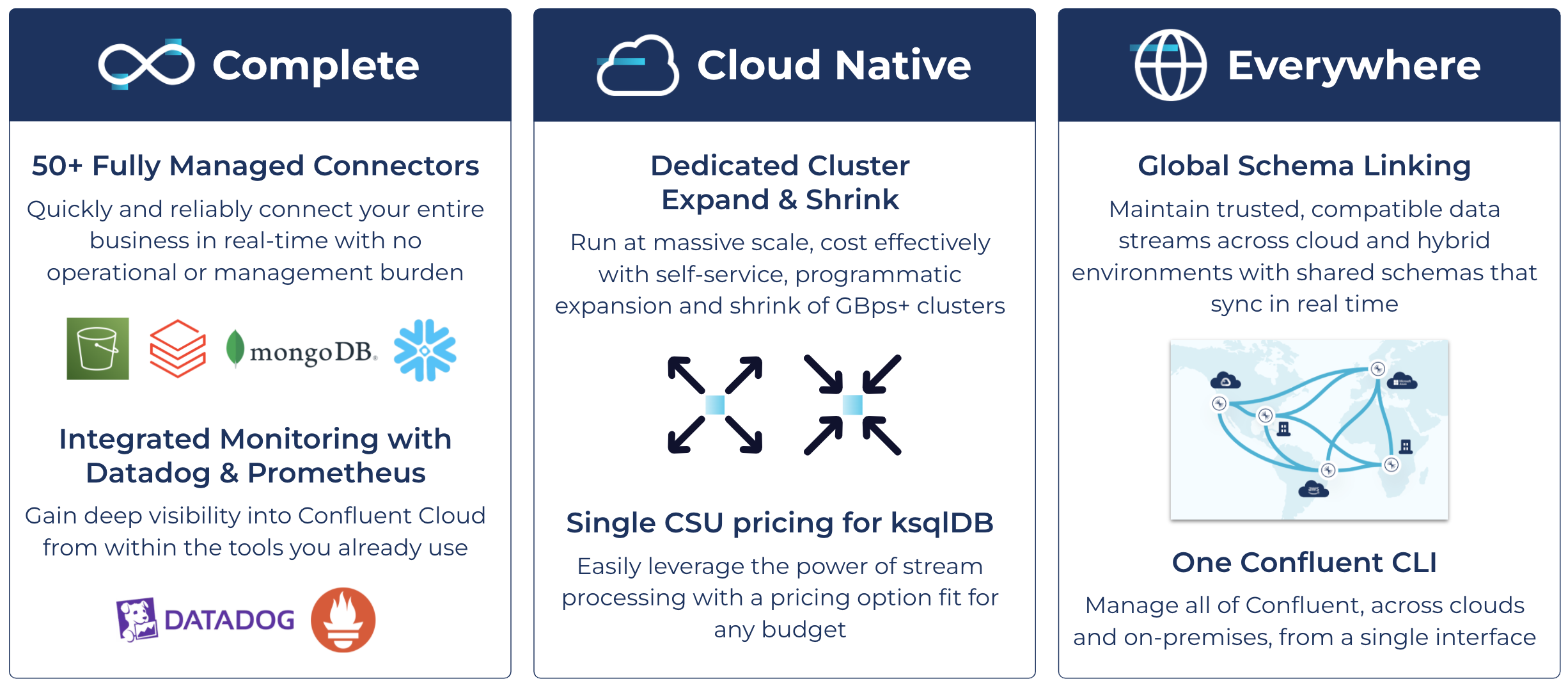
Cloud Native, Complete, and Everywhere: These three pillars are paramount to a data-in-motion platform and structure each of our quarterly launches
Complete: Simplified real-time data integrations with 50+ fully managed connectors
Providing both customers and internal decision-making teams with real-time experiences requires integrating data systems and apps from across your entire business—an ever-evolving challenge. With firsthand knowledge of what it takes to stand up and manage a custom source or sink integration—~3–6 engineering months and deep Kafka expertise—we’re excited to announce the availability of 50+ fully managed connectors on Confluent Cloud. This is the largest portfolio of fully managed connectors in the market and includes more than 30 new connectors since our last quarterly launch! Our fully managed connectors eliminate operational overhead and are packed with productivity features like single message transforms and data previews, enabling teams to accelerate their data in motion journey and lower their total cost of ownership (TCO) for Apache Kafka®.
With our new first-class integrations for Datadog and Prometheus, gain deep visibility into Confluent Cloud from within the monitoring tools you already use.
Learn more about all the updates to our Complete pillar
Cloud native: Massive-throughput elasticity with Dedicated cluster expand and shrink
Teams across every industry working with Apache Kafka face the challenge of ensuring their services remain highly available at all times, no matter what. This is a highly expensive, time-consuming, and risky effort, especially for high throughput use cases. Confluent’s Dedicated clusters now allow customers to run their largest workloads more cost effectively with self-service, programmatic capacity shrink available alongside the previously existing capacity expansion. With controls available through the Confluent Cloud UI, CLI, and API alongside built-in safeguards like automatic load re-balancing, you can dynamically expand capacity to handle any workload, then shrink it back down to control costs without updating clients.
New single CSU application sizes available within ksqlDB provide pricing options fit for any budget, meaning more teams can leverage the power of stream processing.
Learn more about all the updates to our Cloud Native pillar
Everywhere: Globally controlled data quality with Schema Linking
Globally consistent data quality controls are critical for maintaining a highly compatible Kafka deployment fit for long-term, standardized use across the organization. With Schema Linking, you now have an operationally simple means of maintaining trusted, compatible data streams across cloud and hybrid environments with shared schemas that sync in real time. Leveraged alongside Cluster Linking, schemas are shared everywhere they’re needed, providing an easy means of maintaining high data integrity across the entire business.
Additionally, manage all of Confluent, across clouds and on-premises, from a single interface with the new Confluent v2 CLI.
Learn more about all the updates to our Everywhere pillar
Start building with features in the Confluent Q1 ‘22 Launch
Ready to get started? Be sure to register for the Q1 ‘22 Launch demo webinar where you’ll learn how to put these new features to use!
And if you haven’t done so already, sign up for a free trial of Confluent Cloud. New signups receive $400 to spend within Confluent Cloud during their first 60 days. Use the code CL60BLOG for an additional $60 of free usage.*

Complete: Seamlessly connect your entire business in real time with 50+ fully managed connectors
To deliver real-time experiences, companies need high-performance, streaming data pipelines across all of their business systems and apps.
We’re excited to announce our milestone of over 50 (and counting) fully managed connectors on Confluent Cloud—the largest portfolio of fully managed connectors in the market. Our newest additions include ActiveMQ source, Databricks Delta Lake sink, Google BigTable sink, IBM MQ source, MQTT source, MQTT sink, PagerDuty sink, RabbitMQ source, RabbitMQ sink, Redis sink, SFTP source, SFTP sink, Splunk sink, and Zendesk source connectors.
With Confluent’s fully managed connectors, you’re able to:
- Eliminate operational burdens of self-managing connectors and reduce total cost of ownership with the only portfolio of 50+ expert-built, fully managed connectors in the market
- Operate your business in real time by breaking data silos with high-performance, streaming data pipelines into your data warehouse, database, and data lake
- Improve data portability and developer workflow with rich, out-of-the-box features that seamlessly transform and monitor data within the connector rather than in downstream systems

Our portfolio of 50+ fully managed connectors enables real-time integrations with popular data systems and apps in just a few clicks
“We are a small team tasked with making real-time user interaction data available in our data warehouse and data lake for immediate analysis and insights. By using Confluent’s fully managed Amazon S3, Elasticsearch, Salesforce CDC, and Snowflake connectors, we were able to quickly and easily build high-performance streaming data pipelines that connect our business through Confluent Cloud without any operational burden, accelerating our overall project timeline.”
-Joe Burns, CIO, TeePublic
Our journey to fully managed connectors
We are continuing to make significant investments into our fully managed connector portfolio, as we’ve seen firsthand the challenges that arise when building and managing connectors. For example, developers may use the open source Kafka Connect framework to build custom connectors. This requires significant Kafka knowledge, Connect worker management, and an average of 3–6 engineering months to rigorously design, build, and test each connector.
Confluent offers a pre-built ecosystem of 120+ connectors ready for production use to avoid the challenges of developing connectors. Our next goal was to take pre-built connectors further by offering them as fully managed on Confluent Cloud to remove all of your operational and low-level infrastructure burdens. With fully managed connectors, you can now effortlessly integrate your data systems and shift your focus to business-differentiating projects instead. Only Confluent offers 50+ connectors that are fully managed across the entire stack and enriched with out-of-the-box usability features, built by the world’s foremost Kafka experts.
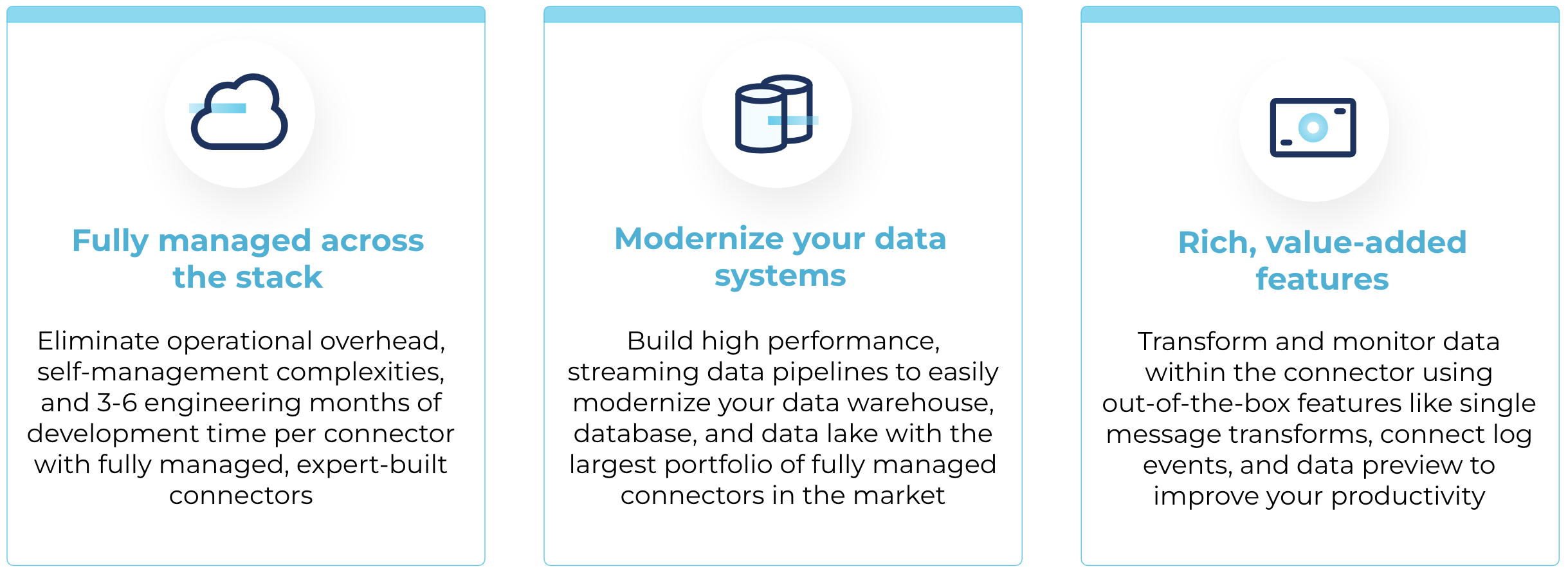
- Fully managed across the stack
Confluent abstracts away complexities around the Connect worker by managing internal topics, worker configs, monitoring, and security, while giving you the control to elastically scale up and down task counts to fit your business needs.While other cloud-hosted Kafka offerings may also manage the underlying Connect worker, they stop short of providing a vast portfolio of fully managed connectors. Without them, you’ll still need to develop, test, maintain, and support each connector in your architecture—missing the opportunity to fully offload non-differentiated development and operational burdens. Additionally, Confluent provides the ongoing support, maintenance, and connector updates you need to power ongoing, mission-critical apps and use cases.
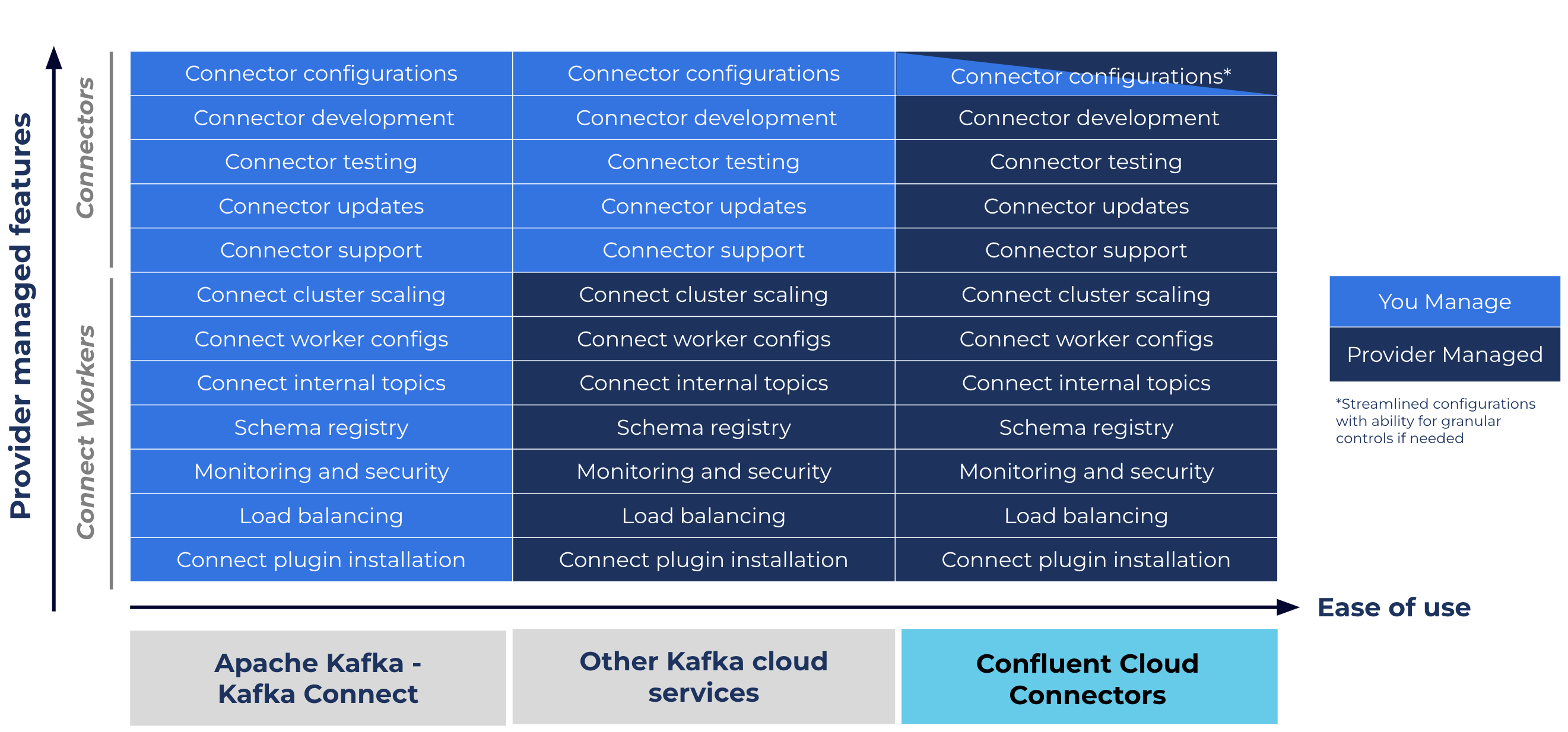
Only Confluent offers expert-built, fully managed connectors across the entire stack to eliminate operational burdens and risks
- Modernize your data systems
Connectors play a critical role in enabling a broad range of streaming use cases, the most popular of which are building streaming ETL pipelines to data warehouses, databases, and data lakes. By moving away from batch processing, you start operating your business in real time.- Data warehouses: Businesses are embarking on the journey to modernize their data warehouse to take advantage of high performance and elasticity at lower costs. Confluent makes it easy to start populating your cloud data warehouse of choice immediately with fully managed sink connectors for Snowflake, Google BigQuery, Azure Synapse Analytics, and Amazon Redshift.
- Databases: Confluent offers fully managed connectors to accelerate the migration from legacy databases to cloud-native options, including MongoDB Atlas, PostgreSQL, MySQL, Microsoft SQL Server, Azure Cosmos DB, Amazon DynamoDB, Oracle Database, Redis, and Google BigTable.
- Data lakes: Populating your data lake through Confluent simplifies your architecture by decoupling your data sources and sinks, streamlining the number of system integrations you’ll have to maintain. We have fully managed sink connectors for Amazon S3, Google Cloud Storage, Azure Blob Storage, Azure Data Lake Storage Gen 2, and have most recently added the Databricks Delta Lake sink connector on AWS.
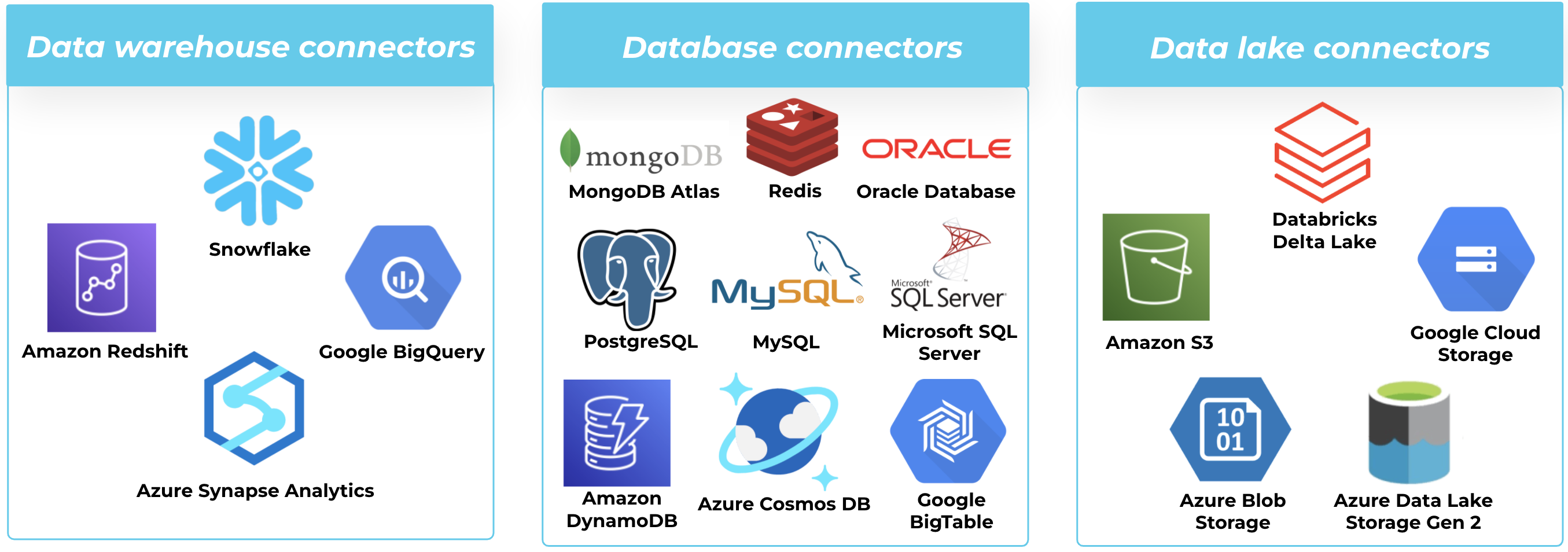
Confluent’s portfolio of fully managed connectors enable you to modernize your data warehouses, databases, and data lakes with real-time data pipelines
- Rich, value-added features: Single message transforms, data preview, and Connect logs
Beyond source and sink coverage, it’s equally important that our fully managed connectors come with rich features to provide additional value at no extra charge and improve your productivity. Over the past quarter, we’ve brought Connect log events and single message transforms (SMTs) to the cloud so that you can monitor connect logs for contextual information and also perform lightweight data transformations, such as masking and filtering messages in flight within the connector. These SMTs improve scalability and reduce the total cost of ownership by eliminating the need for costly, high-volume data processing in downstream systems.Confluent is also the only provider that offers data preview functionality, letting you test a source connector’s output with actual connector configurations prior to launching the connector. This helps with iterative testing, saving you valuable time and enabling you to confidently launch connectors into production.
Complete: Integrated monitoring with Datadog and Prometheus
Maintaining a deep, confident understanding of your entire IT stack is critical to consistently delivering the high-quality services customers demand and expect. However, modern stacks are becoming increasingly complex with the rise of distributed systems and the growing popularity of technologies offloaded to managed services.
Confluent Cloud customers can now use Datadog to monitor their data streams directly alongside the rest of their technology stack. The integration provides businesses with a single source of truth for monitoring and managing mission-critical systems across their entire business and is set up with just a few simple clicks. This allows them to drastically reduce operational complexities when compared to the setup of manual solutions and returns time for focus on higher value-add projects. DevOps teams have easy access to end-to-end visibility of Confluent Cloud within the monitoring tool they already use, providing an easier means to identifying, resolving, or altogether avoiding any issues that may occur.
“Delivering a best-in-class experience for homeowners and housing professionals around the world requires a holistic view of our business. Confluent’s integration with Datadog quickly syncs real-time data streams with our monitoring tool of choice with no operational complexities or middleware required. Our teams now have visibility into the health of all of our systems for reliable, always-on services.” -Mustapha Benosmane, Product leader, ADEO
The new Datadog integration includes:
- Unified monitoring: Monitor the health of Confluent Cloud resources alongside the rest of your technology stack to get a holistic, end-to-end view within a single platform
- Serverless operation: Configure your integration in minutes with just a few clicks and zero ops burden
- Out-of-the-box dashboards: Visualize key cluster health and performance metrics including i/o record counts in a purpose-built dashboard
- Proactive alerting: Set alerts based on performance against user-defined service level objectives (SLOs)
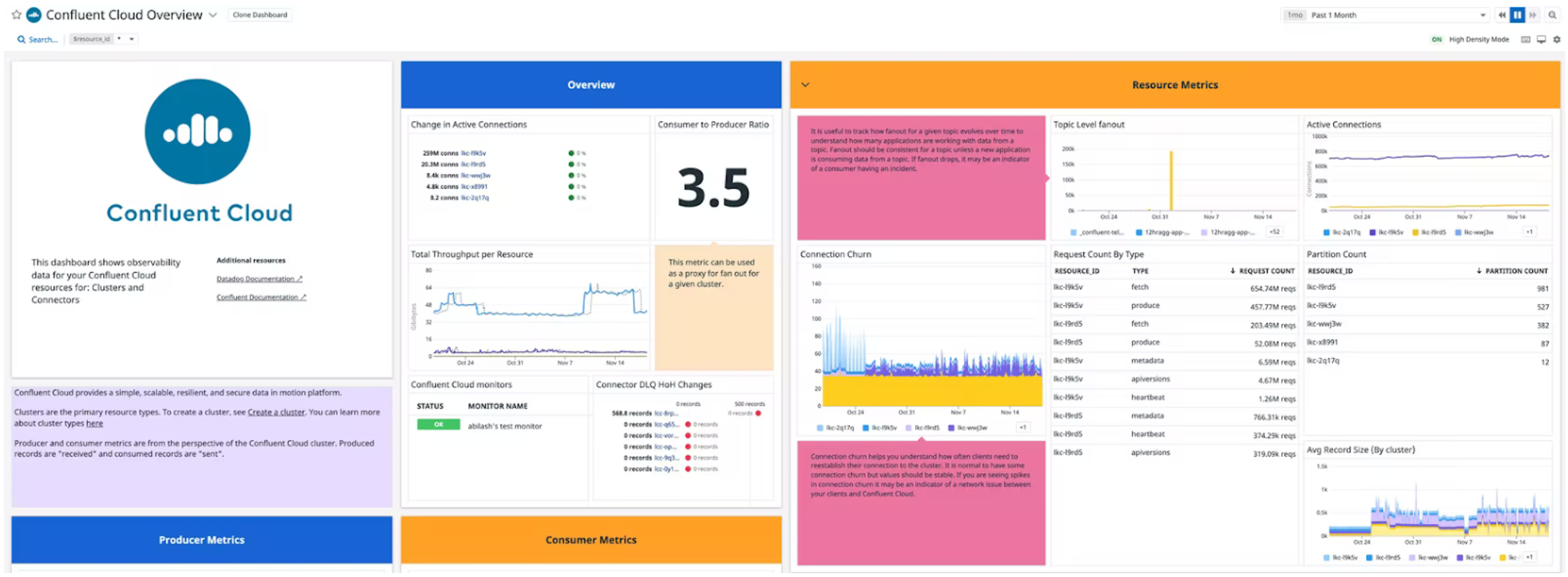
Gain deep visibility into Confluent Cloud from within Datadog’s purpose-built dashboard and visualize key cluster metrics including i/o record counts
For representation of custom data streaming use cases and dashboards within Datadog, Confluent makes it simple to access the data you need with our fully managed Datadog Metrics sink connector.
Alongside our new Datadog integration, Confluent customers can now integrate Confluent Cloud with Prometheus for unified monitoring of data streams within their chosen open source platform by using the new /export endpoint in the Confluent Cloud Metrics API.
The Datadog and Prometheus integrations represent the first of many options we’ll be building for customers to monitor Confluent within their chosen third-party tools.
Complete: Additional updates
- Securely connect to data systems over the public internet with Static Egress IPs (AWS)
Our fully managed connectors now support static egress IP addresses for Confluent Cloud clusters on AWS. Static egress IPs offer an extra layer of security by drastically reducing the attack surface of your data source and sink systems. - BYOK for Google Cloud available in all regions with infinite storage
Bring Your Own Key (BYOK), providing the ability to encrypt data at rest with your own custom key, is now available for Dedicated clusters in all Google Cloud regions with support for Infinite Storage. - ksqlDB is available on Private Link clusters
Stream processing with ksqlDB is now supported on Private Link networked clusters, providing a unique combination of security and simplicity of setup.
Keep a close eye on who is touching your data and what they’re doing with it when consuming our regularly updated supply of audit logs.

Cloud Native: Enhanced elasticity with new controls to expand and shrink GBps+ cluster capacities
This past holiday season, 90 million Americans hit the web shopping on Black Friday, nearly three times the amount shopping online just one day prior. Systems are fortified and over-provisioned in preparation for the unimaginable—a costly and time-consuming preparation, but impossible to argue given the risk. DevOps teams are all-hands-on-deck during these days to ensure spikes in traffic are handled without a hitch. For this reason, we’re excited to announce that Confluent now allows customers to run even their most massive-scale use cases both confidently and cost effectively with self-service cluster expansion and shrinking.
Offered alongside fully serverless Basic & Standard clusters supporting use cases up to 100MBps, our updated Dedicated clusters allow customers to:
- Handle any workload and throughput spike with GBps+ elastically scaling, cloud-native Apache Kafka clusters
- Expand capacity without hesitation and operate cost effectively with self-service, programmatic shrink always available
- Adjust clusters confidently and with operational simplicity with built-in safeguards and automatic load re-balancing
No matter why a traffic spike may occur, data systems are expected to scale seamlessly: up when we need them and back down when we don’t. However, teams working with Apache Kafka have historically had limited options for how to do this:
- When self-managing open source Apache Kafka:
- Capacity adjustments require a complex process of sizing and provisioning of new clusters, networking setup, traffic balancing across new brokers and partitions, and more.
- This process would have to be repeated in reverse once traffic declines in order to cut costs.
- However, expensive capacity far in excess of regularly expected throughput levels is typically maintained in order to avoid the risk of any downtime.
- When using most other managed services for Apache Kafka:
- Added capacity cannot be removed, requiring careful planning and decision making. Expanded clusters will remain at a price point aligned with peak throughput requirements.
- Once expanded capacity is acquired, load balancing is a manual effort.
For businesses seeking to manage a highly available Kafka deployment both cost effectively and with operational simplicity, neither scenario above is an option.
“Ensuring our e-commerce platform is always up and available is a complex, cross-functional, and expensive effort, especially considering the major fluctuations in online traffic we see throughout the year. Our teams are challenged to deliver the exact capacity we need at any given time without over-provisioning expensive infrastructure. With a self-service means to both expand and shrink cloud-native Apache Kafka clusters, Confluent allows us to deliver a real-time experience for every customer with operational simplicity and cost efficiency.”
-Cem Küççük, Senior Manager, Product Engineering, Hepsiburada (NASDAQ:HEPS)
Confluent’s Dedicated clusters now allow customers to manage costs easily with self-service, programmatic capacity shrink. Confluent Units for Kafka (CKUs), with a standard of ~50 MBps ingress and ~150 MBps egress capacity, can be both added or removed at any time through the Cloud UI, CLI, or API. This gives businesses the options they need to run their most sensitive, high-throughput workloads with high availability, operational simplicity, and cost efficiency.
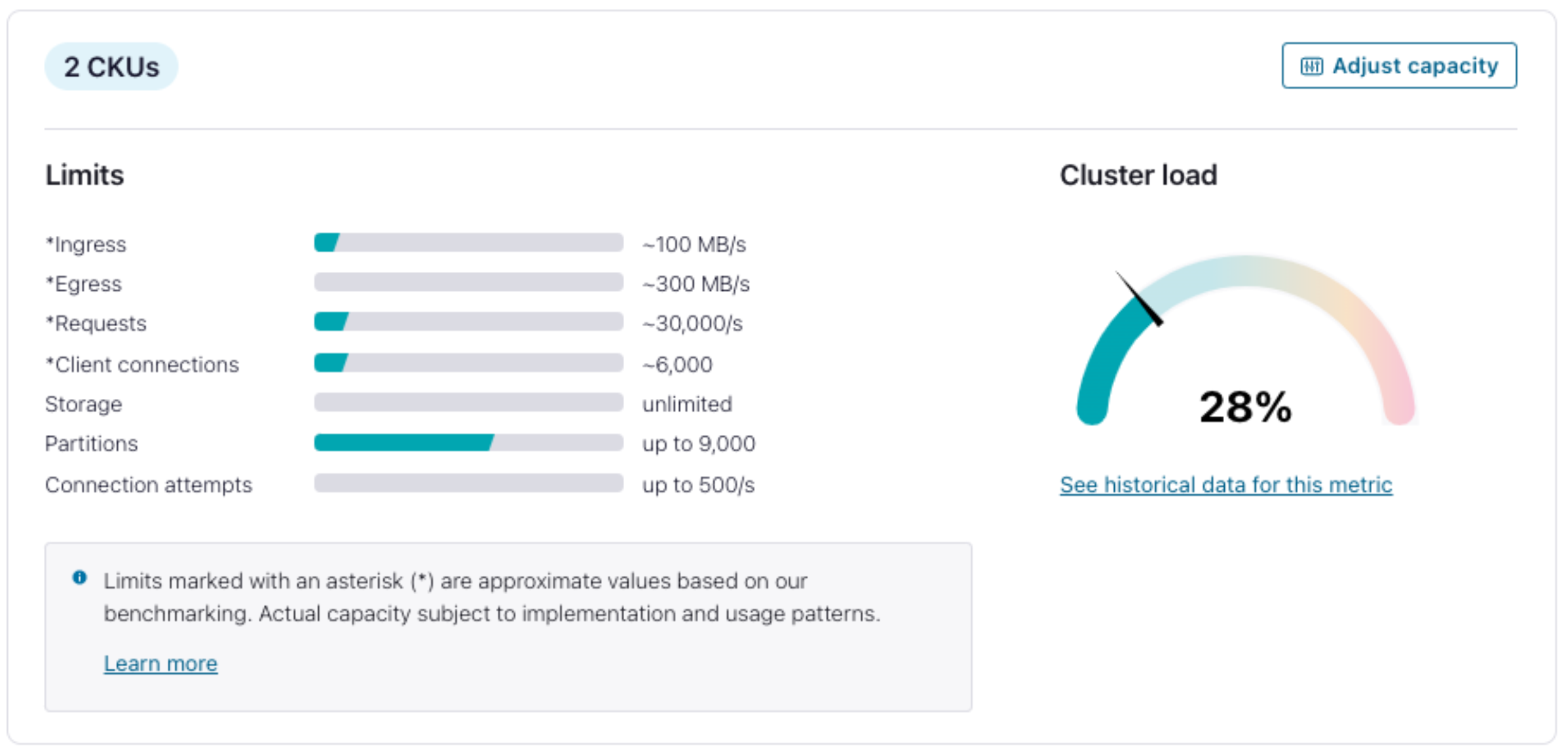
CKUs with ~50 MBps ingress and ~150 MBps egress capacity can be added or removed as needed from Dedicated clusters through the Cloud UI, CLI, or API
Successfully expanding and shrinking CKU counts relies on automatic load rebalancing in order to optimize IO, throughput, and take advantage of the extra resources. This occurs transparently to you and your clients. Upon expanding a cluster, the newly provisioned capacity is immediately allocated towards the data with the highest demand, reducing the load on existing CKUs. Shrinking clusters, in contrast, can only be performed when demand is sufficiently low, so that the newly reduced capacity doesn’t compromise existing workloads. We first rebalance the cluster to help ensure an evenly balanced load across the remaining infrastructure and then remove the unnecessary machines.
With our new Load Metric API, another monitoring update included within this launch, you can maintain an always-on pulse of utilization on your Dedicated clusters in order to make immediate, informed decisions for when to expand and when to shrink. With APIs available for both utilization monitoring and cluster capacity adjustment, downtime as a result of capacity limits can be eliminated with programmatic expansion to support unforeseen traffic spikes. When traffic reverts back to normal levels, scale down to manage costs.
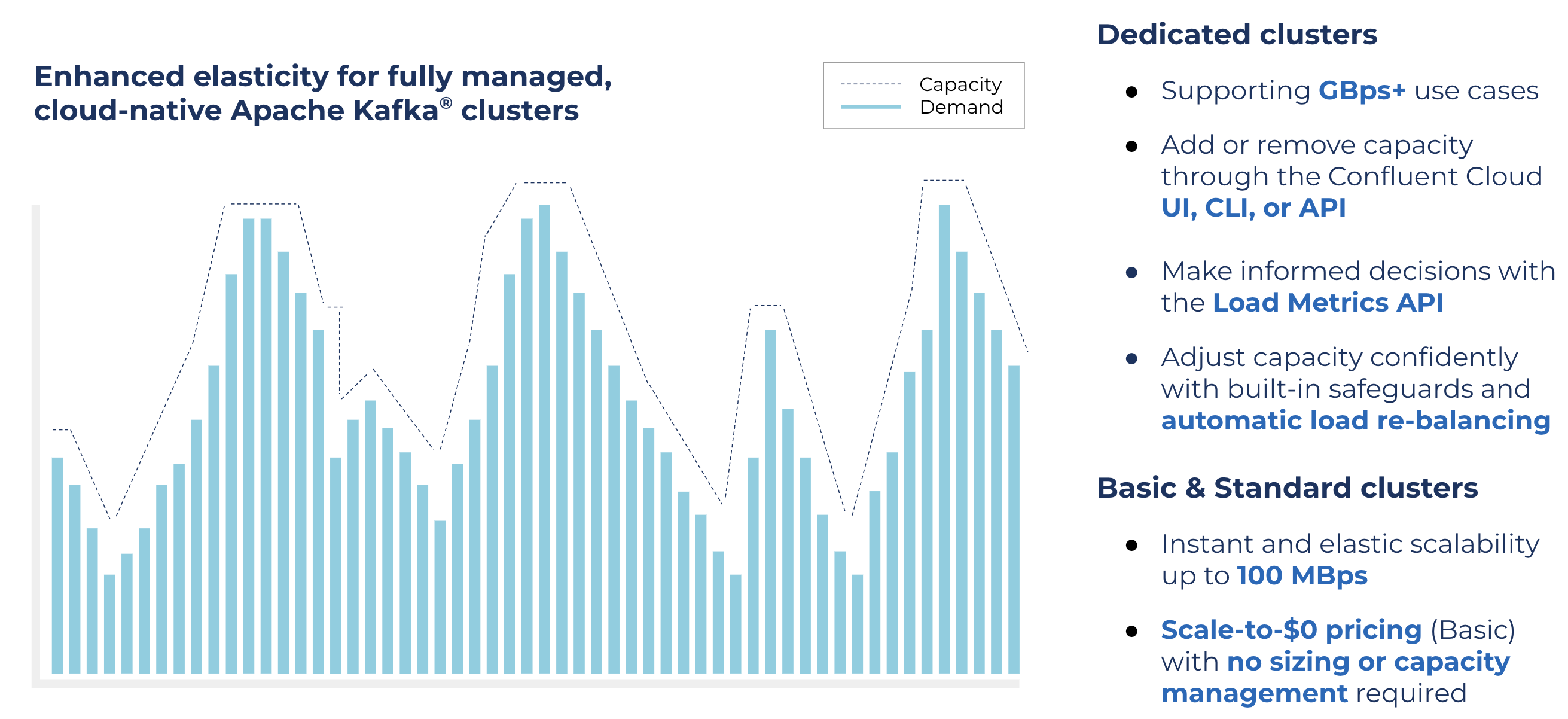
Run at massive scale, cost effectively with self-service cluster expansion and shrink
Alongside our Dedicated cluster, our Basic and Standard clusters provide instant and elastic scalability up to 100 MBps, with the Basic cluster scalable down to a $0 cost.
Cloud Native: Single CSU pricing for ksqlDB
ksqlDB applications are priced by hourly usage of linearly scaling Confluent Streaming Units (CSUs). To make stream processing more accessible to any organization, Confluent is introducing new pricing options to provision ksqlDB applications with only one or two CSUs, down from a previous minimum of four. This enables organizations to get started with stream processing at a cost-efficient price point with options to increase CSUs as workloads grow—setup with 1, 2, 4, 8, or 12 CSUs is available. Customers can now easily leverage the power of stream processing with a pricing option fit for any budget.
Cloud Native: Additional updates
- Automate the provisioning, configuration, and management of clusters
Cluster Management APIs provide operations to list, create, read, update, and delete any cluster within your Confluent environments. - Manage topics, consumers, ACLs, and more via API
The Cluster Administration API provides a simple, familiar, and universal way to build complex, custom workflows with a serverless solution in the language of your choice. Available for both public internet endpoint and VPC-peered clusters, you can now programmatically administer your cluster with:- Creation, management, and deletion of topics
- Management of cluster configurations
- Management of Access Control Lists (ACLs)
- Management of Cluster Linking configurations (for public internet endpoint clusters)
- Automate user, Service Account, and Environment lifecycles with Public REST APIs
New public REST APIs for programmatic management of users, service accounts, and environments are now generally available, allowing for automation of tasks including environment creation, service account provisioning, or even deletion of user accounts when they leave the organization.

Everywhere: Maintain trusted data streams across cloud and hybrid environments with global Schema Linking
As Kafka usage grows to support more mission-critical workloads within an organization, so too does the need to maintain and ensure high data quality. With Schema Linking, now generally available within Confluent Cloud, you have an easy way to ensure consistent schemas and data quality across your cloud and hybrid environments. You can:
- Build a globally connected and highly compatible Kafka deployment with shared schemas and perfectly mirrored data
- Ensure data compatibility everywhere with operational simplicity by leveraging cluster linking and shared schemas that sync in real time
- Share schemas to support every cluster linking use case including cost-effective data sharing, multi-region data mirroring for disaster recovery, and cluster migrations
Cluster Linking made it easy for teams to connect independent clusters across regions, clouds, and hybrid environments in order to fuel their global businesses with a ubiquitous and reliable supply of real-time data. However, operating with connected clusters across environments introduces an increased need for globally enforced standards around data quality. Each new linked cluster brings with it the challenge of maintaining data compatibility and regulatory compliance with information security policies. Ensuring evolving schemas are always up to date and in sync across environments is a challenge to solve. However, finding a solution is necessary as spending expert developer time on schema management and resolution, each time there is a breakage, is unacceptably high.
“Data in motion spreading throughout our business and across teams introduces new challenges related to data quality and compliance. With schemas linked across global clusters that sync in real time, Confluent allows our teams to expand our use of Apache Kafka and innovate quickly without bypassing the controls we need in place to ensure a long term, consistent supply of high-quality data is always maintained.”
-Rikus Swanepoel, Integration Architect, Woolworths
As the latest update to our Stream Governance suite, Schema Linking now gives businesses an operationally simple means of maintaining trusted, compatible data streams across cloud and hybrid environments with shared schemas that sync in real time for both active-passive and active-active setups. Schemas are shared everywhere they’re needed, providing an easy means of maintaining high data integrity while deploying critical use cases including global data sharing, cluster migrations, and preparations for real-time failover in the event of disaster recovery.
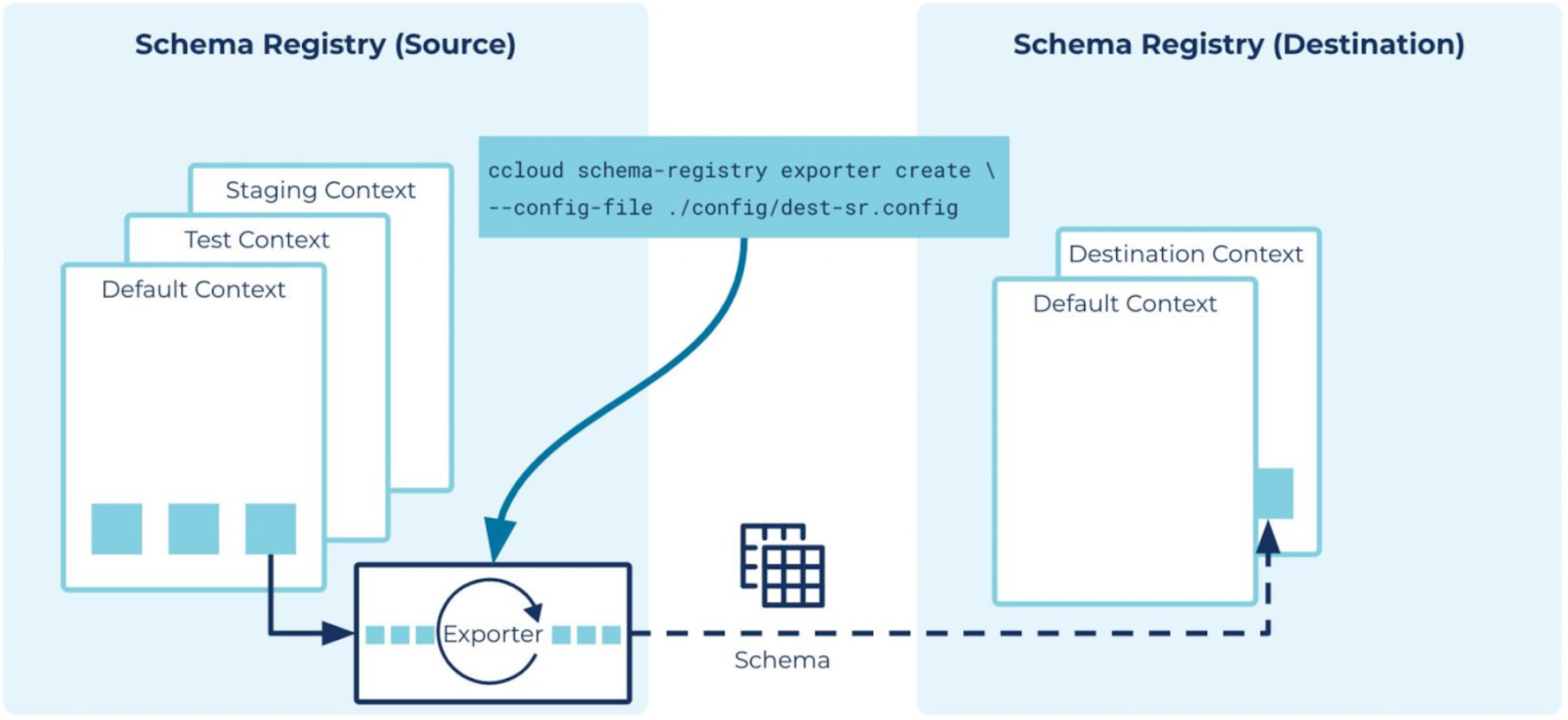
Maintain trusted data streams across environments with shared schemas that sync in real time
Two new concepts are introduced to Schema Registry to bring real-time Schema Linking to life:
- Schema exporters move schemas from one cluster to another, linking them with shared rules for data quality. This exporter is like a mini connector between the two environments performing real-time change data capture of schema updates to ensure the two always stay in sync. The schema exporter is easily managed via API for creation, pausing, resuming, and deletion of the schema link.
- Schema contexts allow for the creation of any number of separate sub-registries within one Schema Registry cluster to facilitate schema exports. Like a namespace, each schema context is an independent grouping of schema IDs and subject names, allowing the same schema ID in different contexts to represent completely different schemas. This enables importing schemas to a new cluster while preserving the schema IDs and subject names from the original. Additionally, schema contexts allow you to separate schemas used for testing or pre-production from those used in production, all in the same cluster.
Everywhere: One Confluent CLI
With the growing popularity of managed services and third-party technologies sitting within the IT stack, it’s becoming increasingly more challenging for engineering organizations to efficiently work with and manage their entire system.
Confluent’s new CLI, confluent v2, provides teams with a one-stop solution for managing all of their data streams—across clouds and on premises—from a single interface. Whether managing an on-premises deployment, provisioning a new cluster in the cloud, or even linking the two together, all of this and more can now be handled through a single tool.
Check out the migration guide for the new CLI and instructions for downloading the new client.
Everywhere: Additional updates
- Auto-created mirror topics for Cluster Linking
Prioritized and built based upon popular customer feedback, auto-creation of mirror topics means DevOps teams no longer need to run an API call for every mirror topic they want to create with Cluster Linking. Users can configure their cluster link to automatically create mirror topics for any topics that exist on the source cluster, saving both time and scripting effort.
Get started with features in the Confluent Q1 ‘22 Launch
Ready to get started? Register for the Confluent Q1 ‘22 Launch demo webinar for quick guidance on how to get up and running with these new features. This demo webinar will provide you with everything you need to get started with all the latest capabilities available on our cloud-native data streaming platform, Confluent Cloud.
And if you haven’t done so already, sign up for a free trial of Confluent Cloud. New signups receive $400 to spend within Confluent Cloud during their first 60 days. Use the code CL60BLOG for an additional $60 of free usage.*
Learn more about the updates to Confluent Cloud within our release notes.
The preceding outlines our general product direction and is not a commitment to deliver any material, code, or functionality. The development, release, timing, and pricing of any features or functionality described may change. Customers should make their purchase decisions based upon services, features, and functions that are currently available.
Confluent and associated marks are trademarks or registered trademarks of Confluent, Inc.
Apache® and Apache Kafka® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by the Apache Software Foundation is implied by the use of these marks. All other trademarks are the property of their respective owners.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...