Kafka in the Cloud: Why it’s 10x better with Confluent | Find out more
Stream Governance – How it Works
At the recent Kafka Summit, Confluent announced the general availability of Stream Governance–the industry’s only governance suite for data in motion. Offered as a fully managed cloud solution, it delivers a simple, cloud-native, and self-service experience that enables users to discover, understand, and trust the real-time data flows in a modern business.
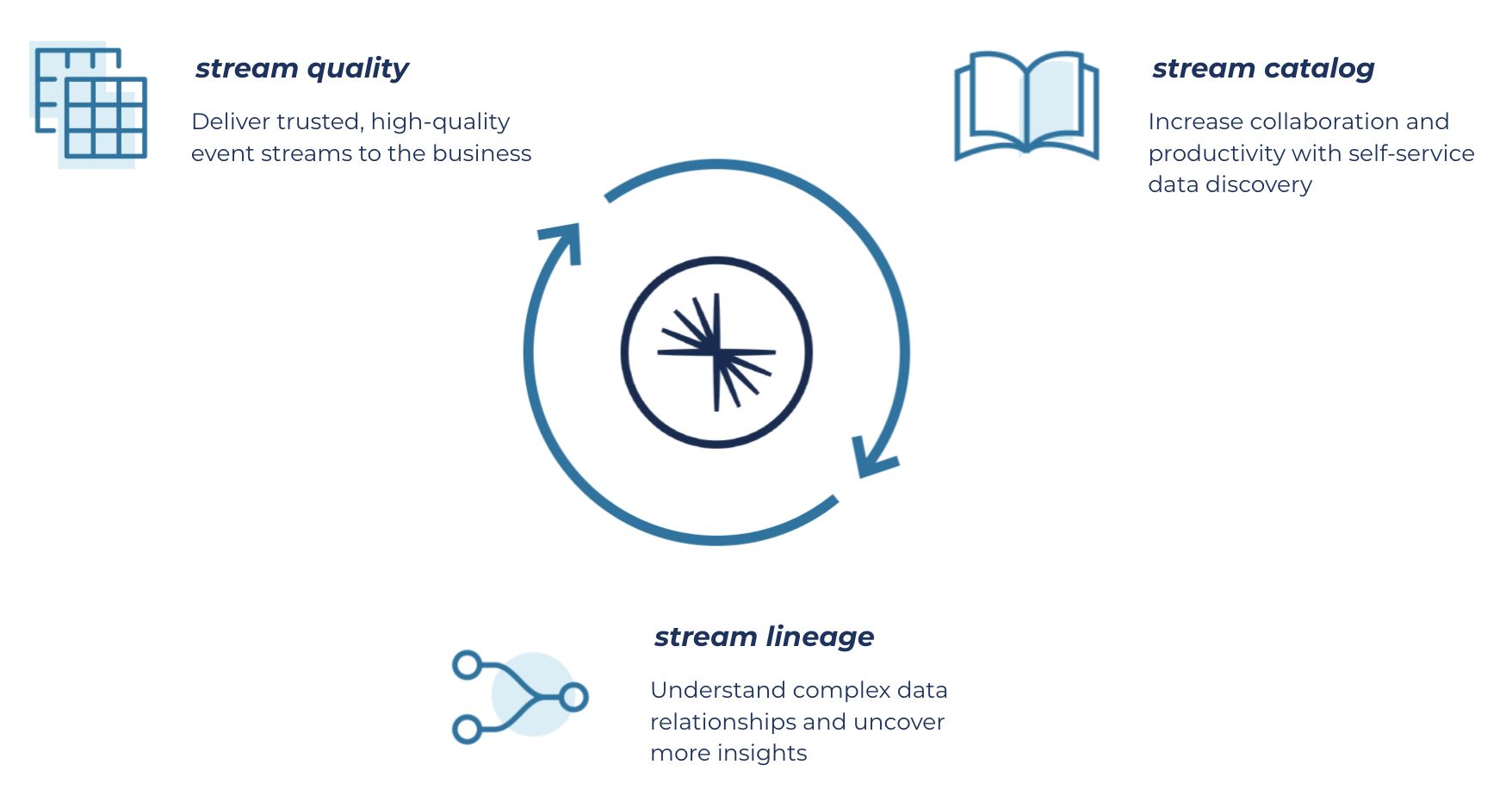
Stream Governance is built upon three key strategic pillars:
- Stream quality: Deliver trusted, high-quality event streams to the business and maintain data integrity as services evolve
- Stream catalog: Increase collaboration and productivity with self-service data discovery, enabling teams to classify, organize, and find the event streams they need
- Stream lineage: Understand complex data relationships and uncover more insights with interactive, end-to-end maps of event streams
In contrast to data governance offerings available in the market that primarily target data at rest, Stream Governance is purpose built for data in motion.
Introducing the Stream Governance – How it Works blog series
In the course of building and operating the Stream Governance product portfolio, the Confluent engineering team has solved some unique technical challenges on both the frontend and backend. To provide a deep dive into some of those learnings, we are launching the Stream Governance – How it Works blog series.
You might find this blog series useful if…
- You’re a developer trying to leverage Stream Governance APIs to automate key business workflows or just curious to learn how various governance use cases were addressed
- You’re a partner who wishes to integrate your data governance offering with Stream Governance
Let’s take a look at some of the key features of Stream Governance.
Intuitive and delightful UX
Over the past couple of decades, a few common themes have emerged across industries. All organizations are undergoing a digital transformation, regardless of whether they’re operating an oil rig, selling products as a retailer, providing banking services, or helping people hail a ride. Organizations are increasingly dependent upon data for fast and informed decision making. With the rise of data regulations, governance is top of mind for every organization across the globe. Given that almost every function heavily relies on the data to make tactical and strategic decisions, it’s crucial that decision makers have access to trustworthy, self-explanatory data.
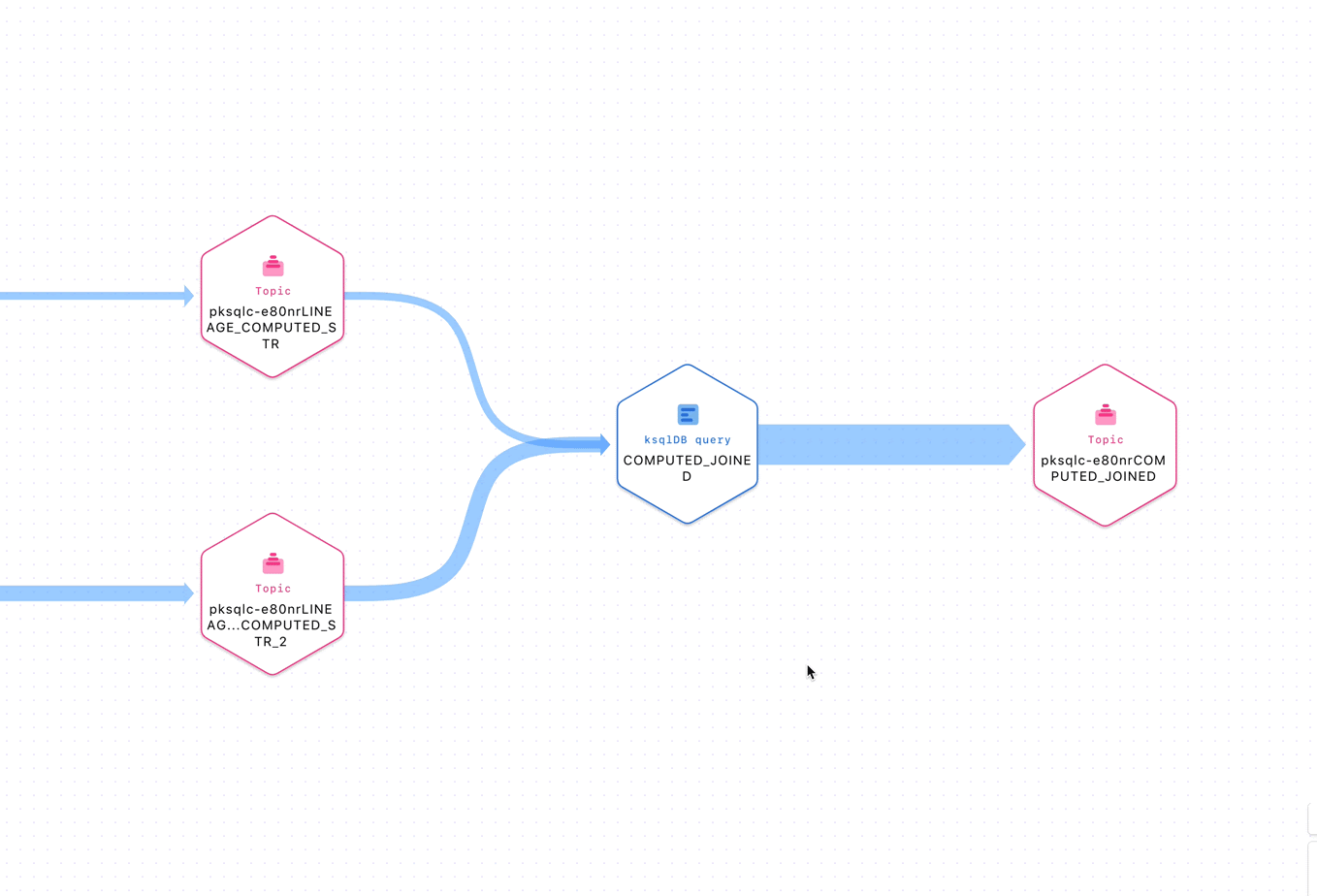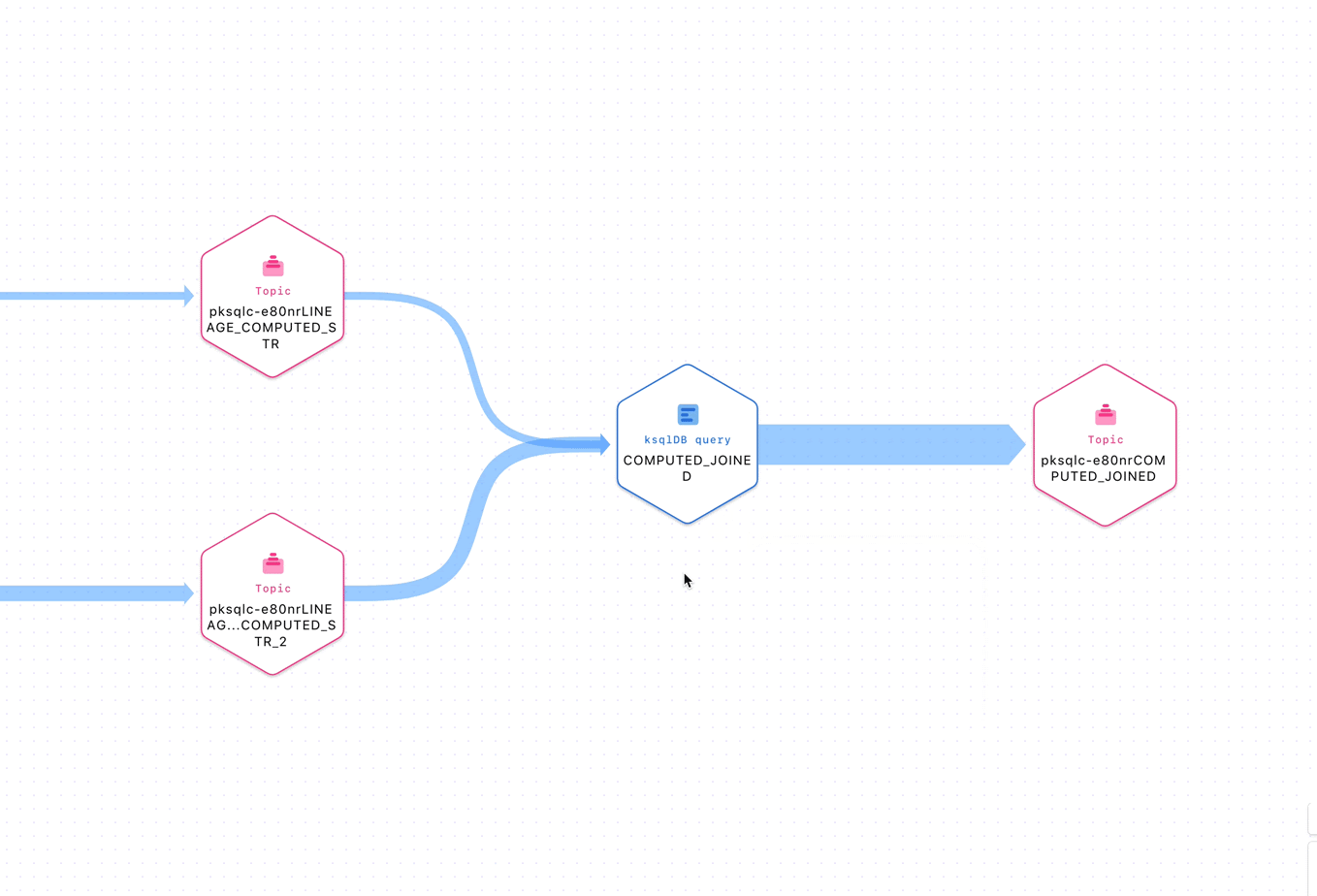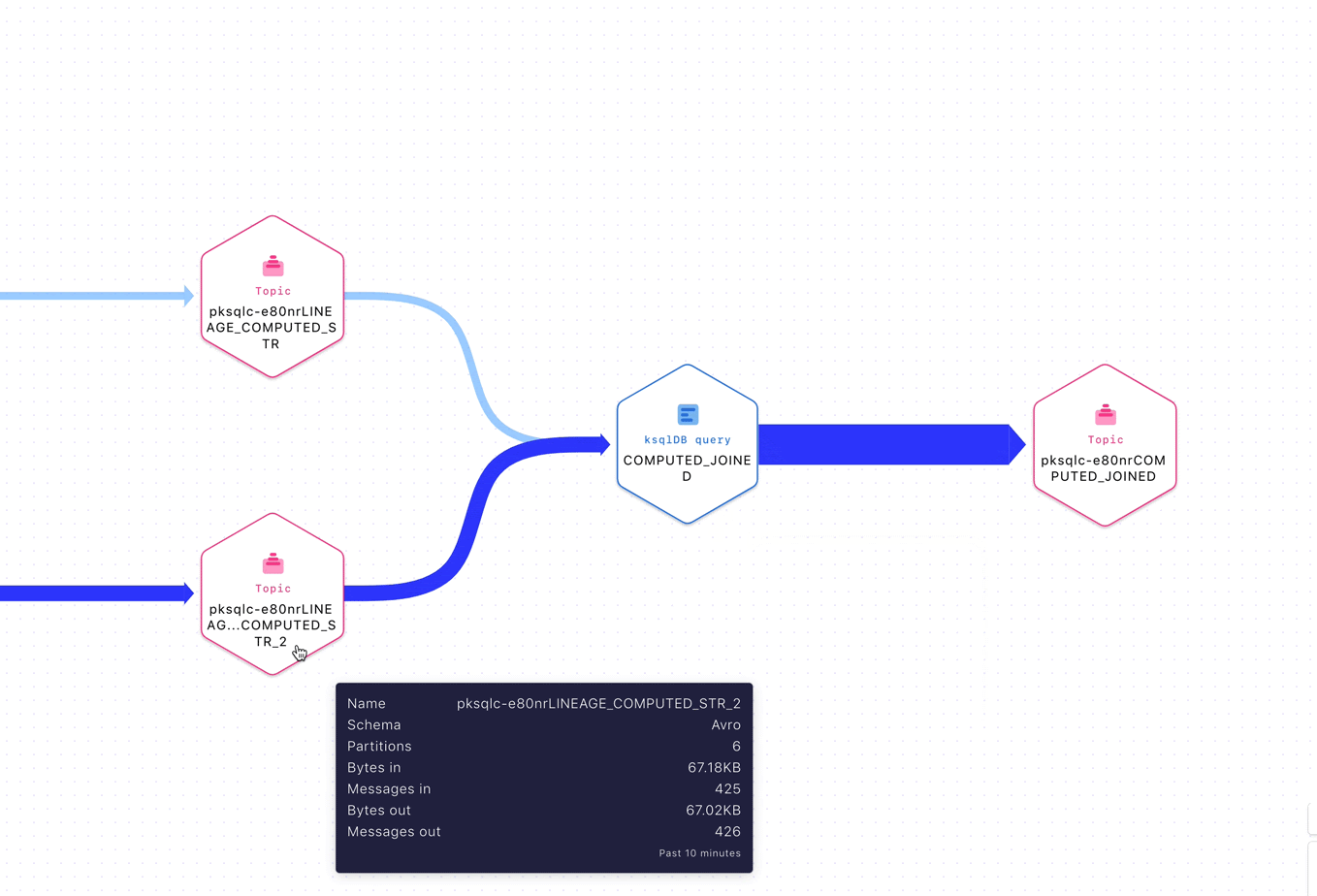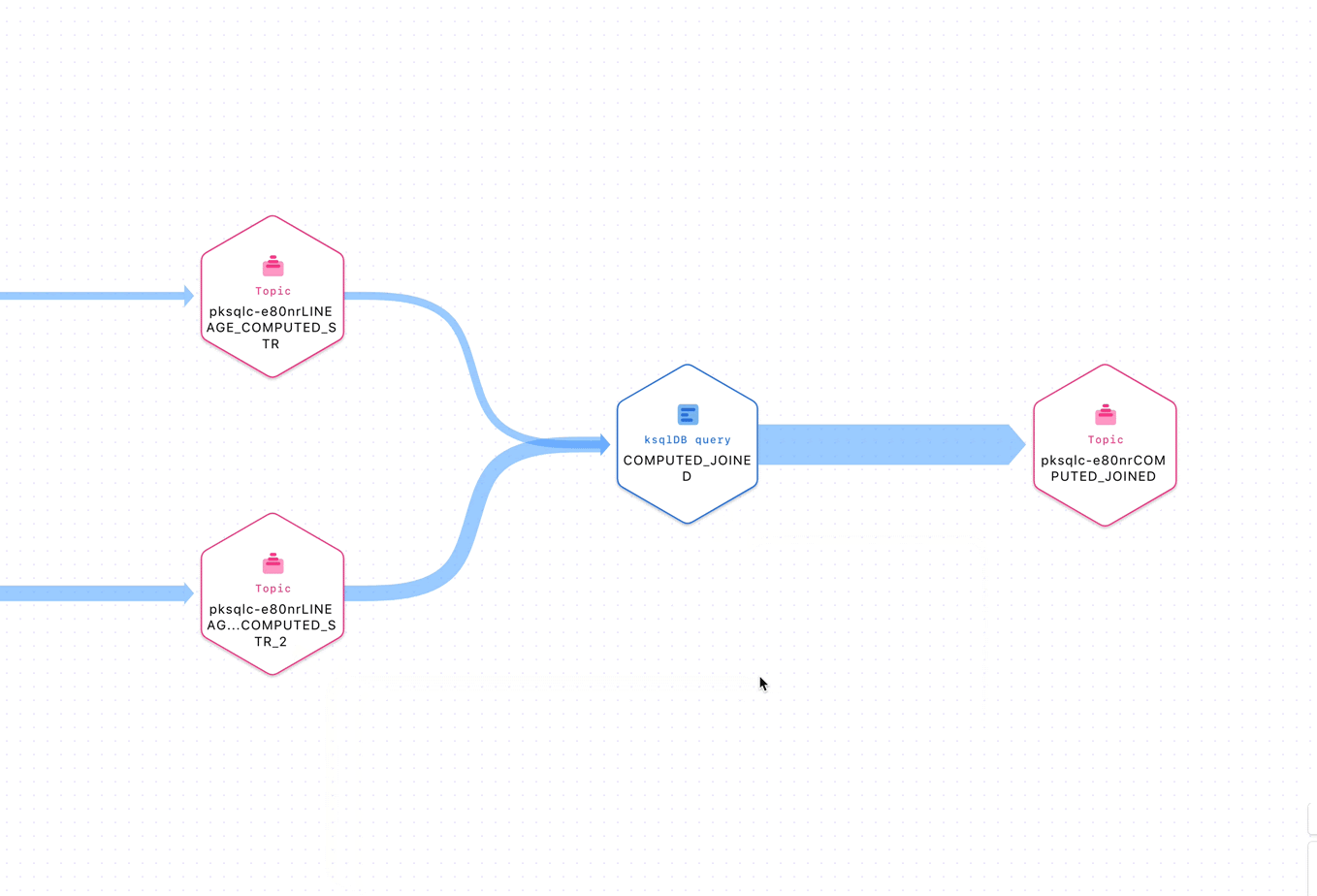
Figure 1: Inspecting entities in a stream lineage topology
Given this context, we have gone the extra mile to ensure a delightful UX in Stream Governance. For example, the stream lineage product exposes real-time topologies to show the journey of data in motion through Confluent in a beautiful canvas. With it, we are able to map all Apache Kafka® applications, including custom producers and consumers, topics, connectors, and ksqDB queries automatically for our customers. With lineage, anyone is able to get a bird’s eye view of how their software interconnects and drill down to specific elements within it.
We strongly believe that a great UX goes beyond just the front end. Let’s consider the schema linking feature, a part of the stream quality pillar, that provides an elegant solution to a complex problem. We are launching its public preview in Confluent Cloud and in Confluent Platform 7.0. It supports the replication of schemas between clusters for purposes of aggregation, backup, disaster recovery (DR), and migration (lift and shift).
Until now, customers have relied on Confluent Replicator to achieve these business-critical workflows. Schema Linking is a better alternative to Confluent Replicator for the following reasons:
- Similar to Confluent Replicator, Schema Linking can be used to migrate schemas from on-premise to Confluent Cloud. It goes a step further and allows for the replication of schemas between two Schema Registry clusters when the source is in the Confluent Cloud.
- Schema Linking has bi-directional data flow between clusters, allowing each side to continue to receive both reads and writes for schemas.
- Schema Linking replaces and extends functionality in Confluent Replicator so that customers have one less component to manage.
Deep integration with every component in Confluent
Enabling Stream Governance takes just a few simple steps and adds no additional operational overhead on your users.
Stream catalog involves deep integrations with every component in Confluent. We transparently instrument entities (such as schemas) to capture the relevant metadata. This metadata is then ingested in stream catalog to power search and discovery workflows. We plan to extend stream catalog functionality to include other entity types such as topics, connectors, and ksqlDB queries.
As shown in this Stream Governance product demo, stream lineage overlays the topology view of the ETL pipeline with the operational health of each node. This is made possible by leveraging the telemetry stack that Confluent has made publicly available.
Stream quality is exemplified by broker-side schema validation. As shown in figure 2, this feature integrates Kafka and Schema Registry to prevent ill-formatted data from being published by enforcing a broker-side schema ID check during a write attempt.
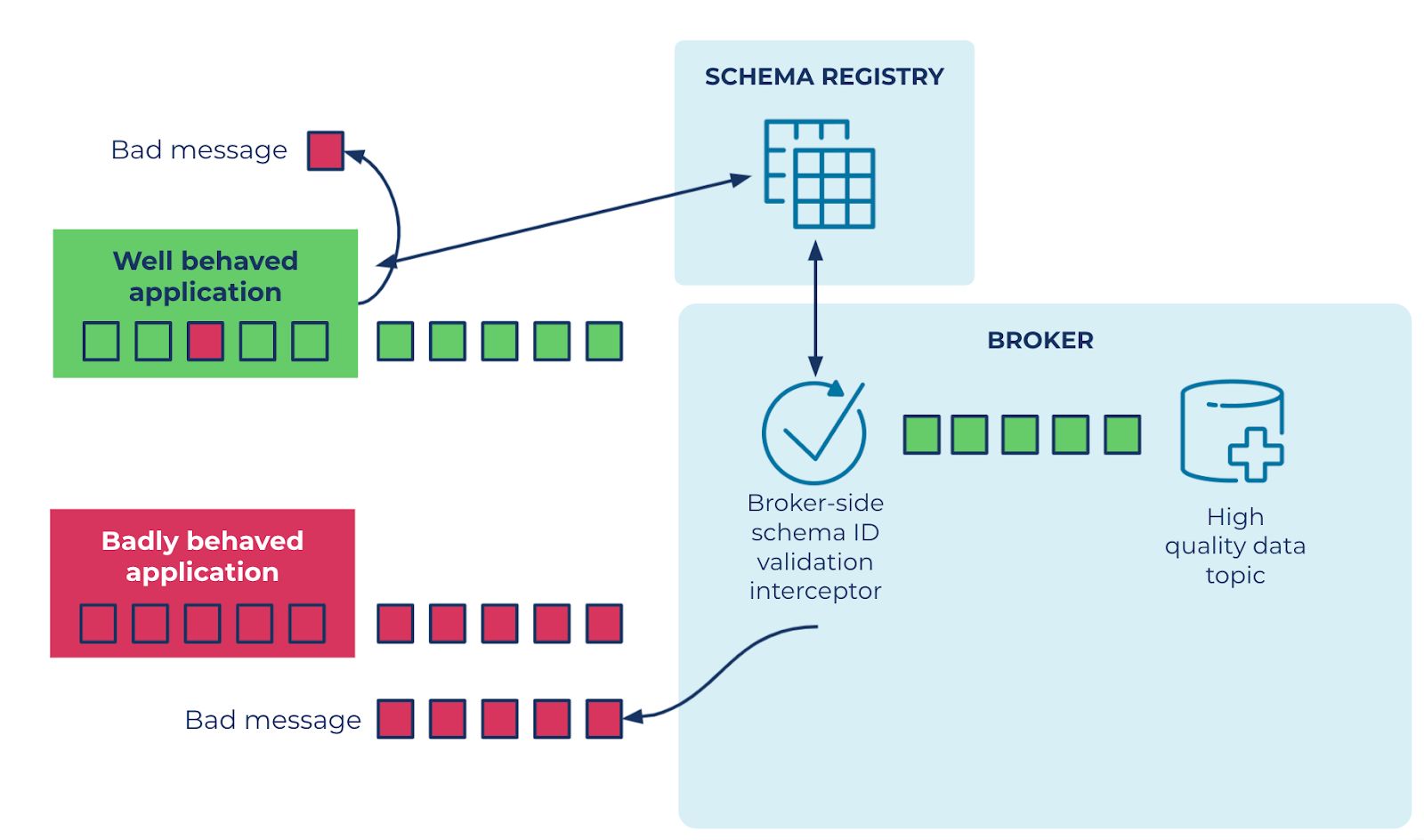
This popular feature, previously launched in Confluent Server, is now also generally available on Confluent Cloud. The communication parameters between the brokers and the Schema Registry (SR) are automatically managed by Confluent, without users needing to perform any action. This reduces operational overhead for customers.
Truly cloud native
With Confluent Cloud, available on AWS, Azure, and Google Cloud, customers can provision Stream Governance on demand in the geographies of their choice. Confluent Cloud is deeply integrated with the marketplaces offered by cloud providers. This enables customers to leverage their cloud provider commits towards Stream Governance. We are actively working on expanding our footprint in additional regions & introducing advanced options for private networking.
Most importantly, leveraging a cloud-native platform means running with the confidence that it is always available, reliable, and up to date. Our highly available clusters are backed by a formal SLA and are upgraded and patched in the background like a true cloud-native service.
Battle-tested
Customer feedback is an essential part of ensuring that we’re building the right thing for our users, which then allows us to offer the best support possible. Over the past few quarters, our team has tirelessly iterated over the product to address feedback from various early access customers.
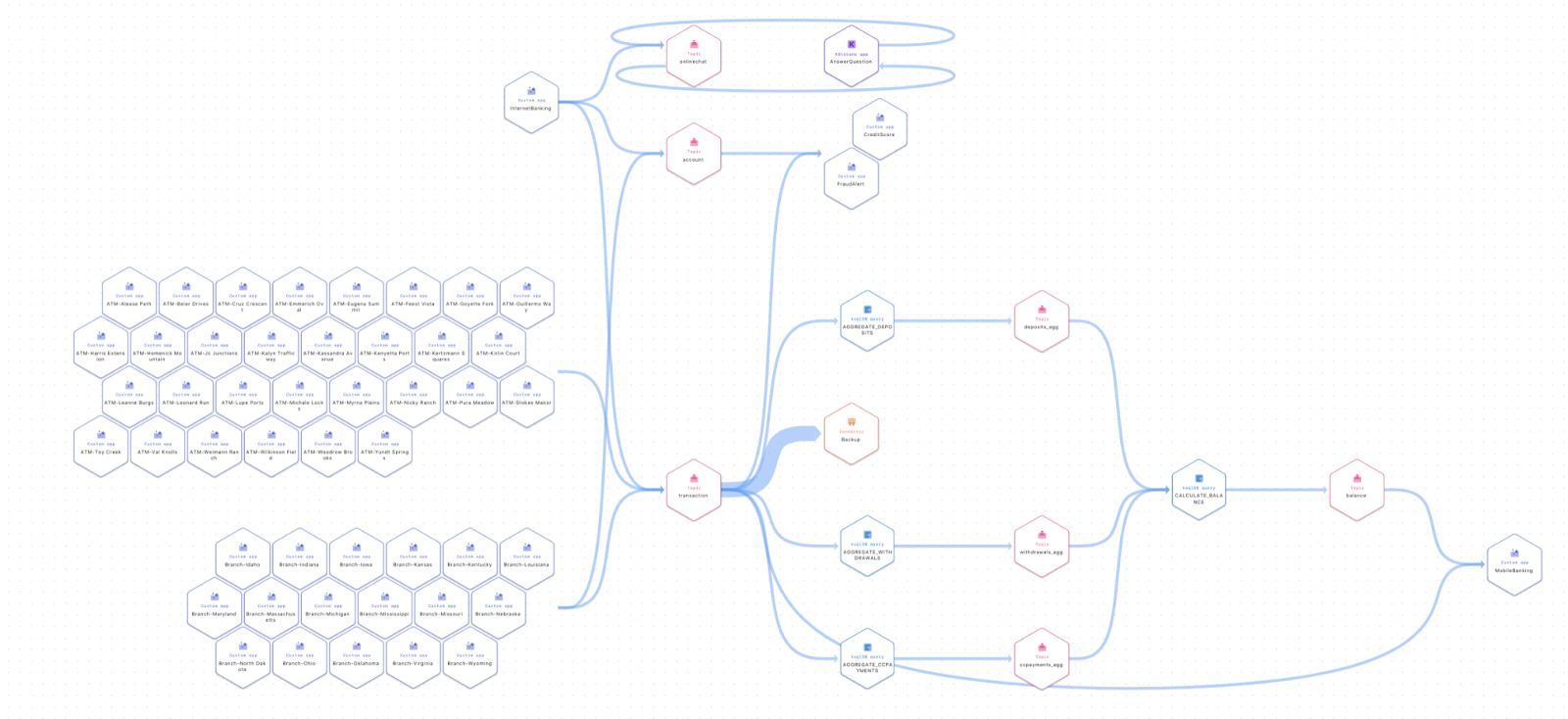
Figure 3: Rendering of a complex topology in stream lineage
During the preview phase of the product, we encountered some topologies that stream lineage wasn’t able to render in a timely manner. By switching to the Canvas libraries in JavaScript, we were able to substantially increase the number of nodes supported by a minimum factor of 10 while also reducing the render time. Additionally, we were able to further reduce render time with a number of other improvements that we will further explore in another installment of this series.
Integration with the partner ecosystem
Customers already leverage a variety of solutions (hosted and self managed) to address their governance needs. Stream catalog APIs will allow our customers to automate their business workflows.
What’s coming next…
We hope you enjoyed this first glimpse into how Stream Governance works. You can also listen to the Streaming Audio to learn more about the topic. Stream quality tools in Stream Governance enable teams to deliver a scalable supply of trusted event streams throughout the business. Stream catalog allows users across teams to collaborate within a centralized, organized library designed for sharing, finding, and understanding the data needed to drive their projects forward quickly and efficiently. Stream lineage provides a bird’s eye view and drill-down magnification for answering questions on important subjects like data regulation and compliance.
In the upcoming installments of this blog series, you’ll learn how we built Schema Linking to enable active/active and active/passive replication of schemas and how we tackled various challenges while building the stream lineage frontend. Stay tuned! If there are any topics you would like to hear more about, let us know on the Community Forum or Slack.
We are just getting started on our journey of building a comprehensive, interoperable, decentralized, and fully integrated Stream Governance solution available across cloud, on-premises, and hybrid environments. If you’ve not done so already, make sure to sign up for a free trial of Confluent Cloud to see Stream Governance in action. Use the promo code CL60BLOG for an additional $60 of free Confluent Cloud usage.*
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...